LangGraph vs LangChain
| 方面 | LangChain | LangGraph |
|---|---|---|
| 发布顺序 | 2022 年最早发布(最早的 LLM 应用框架) | 2024 年左右推出,是较新的框架 |
| 核心理念 | Chains(链式): 线性、顺序执行的流程(A → B → C) | Graphs(图):节点(Nodes) + 边(Edges) + 状态(State) 支持循环、分支、条件路由、多代理协作 |
| 擅长场景 | 简单、线性的工作流 (如 RAG、Prompt 串联、基本 Agent) | 复杂、状态 ful、非线性的工作流 (多代理、循环推理、human-in-the-loop、生产级 Agent) |
| 关系 | 基础组件库(提供 LLM、Tools、Memory、Retrievers、Prompts 等) | 构建在 LangChain 之上,复用 LangChain 的绝大部分组件 |
| 是否可以独立使用 | 可以独立使用 | 通常需要 LangChain 的组件支持(虽然可以单独安装,但最佳实践是结合使用) |
| 当前定位 | 快速原型、简单应用、组件集成 | 生产级 Agent Orchestration(编排)框架,被推荐用于复杂场景 |
为什么会出现 LangGraph?
早期 LangChain 用 Chains 和 AgentExecutor 做 Agent 时,遇到很多痛点:
- 流程是线性的,很难优雅地处理循环(循环调用工具)、分支决策、错误重试、持久化状态等。
- 多代理协作、human-in-the-loop、中断恢复等生产需求实现起来很 messy。
于是 LangChain 团队开发了 LangGraph,它:
- 把整个流程建模成一个 有向图(Directed Graph),甚至支持循环图(Cyclic Graph)。
- 每个节点可以是 LLM 调用、Tool 执行、条件判断等。
- 通过 conditional edges(条件边)来决定下一步去哪里(这正是我们之前讨论的“是否结束循环”的判断逻辑)。
- 提供更好的状态管理、checkpoint(持久化)、streaming、可视化(LangGraph Studio)等生产特性。
基础知识
原理概述
LangGraph 基本原理是邻接表与有限状态机(FSM)模型。
创建并编译好的图(graph = builder.compile()),在内存中本质上是一个基于 Pregel(大批量同步并行算法)模型的实例对象。它的骨架是由几个核心的 Python 字典(Dict)和集合(Set) 交织而成的“邻接表”变体。
如果我们把内存扒开,图的结构主要由以下四个核心部件存储:
1. 节点存储:nodes (字典)
在内存中,所有的节点被保存在一个字典里。键(Key)是你给节点起的名字(字符串),值(Value)是被 LangChain 统一包装过的 Runnable 对象。
# 内存中的大概样子:
graph.builder.nodes = {
"__start__": <SpecialStartNodeObject>,
"agent": <RunnableLambda(agent_node_function)>,
"tools": <ToolNodeObject>,
"__end__": <SpecialEndNodeObject>
}
无论你原来写的是普通 Python 函数还是大模型,编译时全都会被强行包裹成标准的 Runnable,方便统一调用。
2. 静态边存储:edges (集合)
普通的连线(A 走完必然走到 B),在内存中是以一个**元组集合(Set of Tuples)**的形式存在的。这也是最经典的图论存储方式——边集。
# 内存中的大概样子:
graph.builder.edges = {
("__start__", "agent"), # 起点指向 agent
("tools", "agent") # 工具执行完指向 agent
}
引擎在运行时,只要看到当前节点运行完了,就会来这个集合里找它的“下一个目标”。
3. 条件边存储:branches (复杂字典)
这是 LangGraph 最复杂的地方。因为条件边不是写死的,它包含一个“判断逻辑”。在内存中,它被存为一个嵌套字典。
- Key: 出发节点的名字。
- Value: 一个包含了路由函数(Router Runnable)和目标映射表(Path Map)的分支对象(Branch Object)。
# 内存中的大概样子:
graph.builder.branches = {
"agent": [
<BranchObject(
condition= <RunnableLambda(should_continue_function)>,
path_map= {
"continue": "tools",
"end": "__end__"
}
)>
]
}
4. 通道映射:channels (发布 - 订阅模型)
这是 LangGraph 底层(Pregel 架构)的精髓。 虽然你觉得节点是直接把数据传给下一个节点的,但在内存的底层实现中,节点之间是互不相见的。它们通过“通道(Channels)”进行通信。
你的 State 字典里的每一个字段(比如 messages, draft),在图编译后,都会变成一个独立的 Channel。
- 节点运行完: 不会直接调用下一个节点,而是向 Channel 里“发布(Publish)”更新。
- 下一批节点触发: 引擎会查看哪些 Channel 被更新了,如果有节点“订阅”了这个 Channel 更新引起的流转,引擎就会把它扔进任务池(Task Queue)去执行。
超步 Superstep
LangGraph 底层所采用的“受 Pregel 启发”的机制,本质上是对 BSP(大容量同步并行,Bulk Synchronous Parallel) 计算模型的现代化应用。
Google Pregel 是谷歌为了解决千亿级网页(如 PageRank 计算)而发明的分布式图计算框架。它打破了传统的“全局视角”编程,要求开发者采用“像顶点一样思考(Think like a vertex)”的模式。Pregel 的核心就是将无休止的计算强制划分为一个个离散的时间周期,这个周期就被称为 “超步(Superstep)”。
一个标准的超步包含以下四个强制阶段(即 BSP 模型):
- 读取消息(Receive): 节点(Agent/函数)读取上一个超步发给它的所有消息。
- 并行计算(Compute): 所有被激活的节点在同一时刻并行执行自己的逻辑。节点之间在计算时互不通信,绝对隔离。
- 生成消息(Send): 节点计算完成后,不直接修改全局状态,而是把结果打包成“消息”,准备发给下一个节点。
- 屏障同步(Barrier Synchronization): 这是超步的灵魂。 系统会设置一堵“墙”(Barrier)。跑得快的节点必须停下来等跑得慢的节点。只有当当前超步中所有的节点都执行完毕后,系统才会统一把所有生成的“消息”投递出去,并正式进入下一个超步。
- 所有节点通过 vote-to-halt 机制声明自己已完成,无新消息时整个计算终止。
LangGraph 直接借鉴了这一架构,将其适配到 LLM 驱动的 agent 工作流 中,并命名为 Pregel runtime。
LangGraph 将图建模为 actors(执行者) + channels(通信通道):
- Actors:即图中的 nodes(PregelNode),每个 node 是一个可执行函数(实现 LangChain Runnable 接口)。它从订阅的 channels 读取数据,执行后向 channels 写入更新。
- Channels:消息传递的媒介(非传统边),支持多种类型:
- LastValue(默认):保留最新值;
- Topic:Pub/Sub,可累积多值;
- BinaryOperatorAggregate:聚合操作(如累加);
- EphemeralValue:临时值等。
- Message Passing:node 执行完后沿 edges 发送消息(状态更新),接收方在下一个 superstep 才看到更新。
LangGraph 超步执行流程
0. 订阅
LangGraph 的 Actors 之间不直接互相调用。底层提供了一种叫做 Channel(通道) 的机制(在用户层通常被抽象为全局 State 字典和 Reducer)。每个 Actor 可以“订阅”特定的 Channel。
一个执行器是一个 PregelNode。它订阅通道,从它们读取数据,并向它们写入数据。它可以被认为是 Pregel 算法中的一个执行器。PregelNodes 实现了 LangChain 的 Runnable 接口。
1. Plan
在每一个超步开始前,调度器会检查哪些 Channel 的数据在上一步被更新了。那些订阅了被更新 Channel 的 Actor ,将在当前的超步中被激活。
- 首次:选择订阅 input channels 的 actors;
- 后续:选择订阅上一步被更新的 channels 的 actors。
2. Execution
所有选中的执行器 actors 并行 执行。
- 直到全部完成、失败或超时;
- 此阶段内 channel 更新对 actors 不可见(隔离性)。
3. Update 延迟写入
这是 LangGraph 区别于普通 LangChain 的关键。 当 actor 在超步内运行结束时,它返回的 State 更新字典不会立刻覆盖真实的全局内存。相反,引擎会把这些更新暂存为 “待处理写入(Pending writes)” 。
4. Checkpointer 状态合并与持久化
当当前超步内所有被激活的 actor 全部运行完毕(到达同步屏障),LangGraph 会做两件事:
- 调用你定义的 Reducer(如
operator.add),将所有“待处理写入”统一合并到真实的全局 State 中。 - 触发 Checkpointer(检查点): 将当前超步的完整状态(版本号、State 快照、下一个要执行的节点等)以离散的形式持久化保存到数据库(如 SQLite/Postgres)中 。
5. vote to halt
至此,一个离散的超步正式结束,系统准备进入下一个超步,重复执行直到没有 actors 被选中执行或达到 recursion_limit。
- 收到新消息(任何 incoming channel 有更新)→ 变为 active 并执行
- 若无 incoming messages,则 vote to halt(标记 inactive);
- 当所有节点初始为 inactive 后,superstep 结束时,
- 当所有节点 inactive 且无在途消息时,图执行终止。
一个超步中所有节点都在等待最慢的节点,效率不是很低吗?
在学术界,这被称为 BSP 计算模型的 “落后节点问题(Straggler Problem)”。既然有这问题,为什么 LangGraph(甚至 Google 处理千亿网页时)还要采用这种带“同步屏障”的设计呢?
因为它在大模型/Agent 的业务场景下,是“利远大于弊”的:
- 跟“串行”比,它已经快得多了
- 避免灾难性的“状态脏读(Race Conditions)”
- 每个通道本质是内存中的“信箱”,程序突然崩溃了,信箱里的信还在(存入了数据库)。“信箱”中的信都有专属的订阅者,信中内容其他人无法查看。
- 网络 I/O 是最大的瓶颈,而不是 CPU
- 如果是在算力密集的科学计算中,让 CPU 闲置等待确实是巨大的浪费。 但在 LangGraph 中,节点通常是在“调用大模型 API”或“请求外部数据库”。这种等待是网络延迟(I/O bound)。节点被挂起等待时,只是在等网络回包,并没有浪费本地电脑极高的 CPU 算力。
超步限制
递归限制(Recursion Limit),限制的是 “超步(Superstep)”的执行总次数。
具体来说,它是为了防止以下几种致命情况:
- 防止大模型陷入“无限纠错”的死循环
- 防止开发者设计的“路由 Bug”(图中有环的情况)
- 限制单次任务的最大深度
- 有时候并不是死循环,而是任务太复杂。比如你让一个 Agent 去网上爬取并总结某个事件的所有信息,它可能不断地触发“搜索 -> 阅读 -> 再搜索新关键词”的循环。 设置
recursion_limit可以强制规定:“不管你找没找全,最多只能搜索/思考 10 轮,到了 10 轮必须给我一个最终答案或者直接报错”。
- 有时候并不是死循环,而是任务太复杂。比如你让一个 Agent 去网上爬取并总结某个事件的所有信息,它可能不断地触发“搜索 -> 阅读 -> 再搜索新关键词”的循环。 设置
5. 主观直视:图是如何“动”起来的?
当你在代码里执行 graph.invoke() 时,底层的 Python 引擎其实就是在对着这几个数据结构做 while 循环(广度优先遍历):
- 引擎查看当前在哪个节点(默认从
__start__开始)。 - 从
nodes字典里把这个节点对应的函数提出来,跑一遍。 - 节点跑完后,把结果更新到内存的白板(Channels)上。
- 引擎去查
edges集合和branches字典,问:“这个节点跑完了,下面该谁上场?” - 找到下一个节点,把它们放进“准备执行列表”。
- 循环往复,直到要执行的下一个节点是
__end__,图执行结束。
所以,图的结构在内存中绝对不是 JSON,而是一个由 Dict、Set、Runnable 和 Channel 对象高度耦合组合而成的邻接表与有限状态机(FSM)模型。
6. 客观底层:图是如何“动”起来的?
你知道了有向图可以用领接表存储,而领接表可以通过数组实现? LangChain 节点、节点与节点之间的数据是怎么保存的?如何遍历?
LangGraph 在内存中并不是用单纯的“邻接表”来保存图的。 为了实现大模型的并发调用、随时暂停(中断)和状态持久化,LangGraph 在执行 graph.compile() 时,做了一次架构转换:它把“点与点的连线”,转换成了基于 Pregel 模型的“发布 - 订阅(Pub/Sub)通道”。
- Compile 之前
在写 builder = StateGraph(...) 并调用 add_node 和 add_edge 时,内存中的数据结构确实非常接近想象的“邻接表”。这个时候的数据是非常朴素的 Python 字典和集合:
builder.nodes(字典): 保存节点。
{
"agent": <Runnable对象>,
"tools": <Runnable对象>
}
builder.edges(集合): 保存静态的连线。
{
("agent", "tools"), # 一条从 agent 到 tools 的边
("tools", "agent")
}
builder.branches(字典): 保存条件边(路由判断)。
{
"agent": {"condition_function": <函数>, "path_map": {"end": "__end__", "continue": "tools"}}
}
但这只是“图纸”。这个结构是无法直接运行大模型智能体的。
- Compile 之后
内存中有一个巨大的 nodes 字典。但这里面的值不再是原来写的那个简单函数,而全都被包装成了 PregelNode 对象。条件边(动态路由)转为 Dynamic ChannelWriter。在内存中被存为了特殊的“路由写入器(ChannelWrite)”。
# 编译后内存中的真实样子(高度简化版概念图):
# 无条件边
graph.nodes = {
"agent": PregelNode(
bound=<原始函数>,
triggers=["__start__", "tools"], # 触发器:谁能唤醒我?
writers=["agent_output_channel"] # 写入器:我执行完要往哪个通道发广播?
),
"tools": PregelNode(
bound=<原始函数>,
triggers=["agent_output_channel"],
writers=["tools"]
)
}
# 加入条件边
graph.nodes = {
"agent": PregelNode(
bound=<原始大模型函数>,
# 谁能唤醒我?起点,或者工具执行完毕
triggers=["__start__", "tools_finish_channel"],
# 写入器:我执行完要往哪个通道发广播?这里是一个“动态分支分发器”
writers=[
RunnableBranch(
condition=<定义的路由函数,比如 check_tool_call>,
path_map={
# 如果路由函数返回 "use_tool",就动态向 "tools_trigger_channel" 扔信
"use_tool": ChannelWrite(channels=["tools_trigger_channel"]),
# 如果路由函数返回 "finish",就动态向 "__end__" 通道扔信,结束图的运行
"finish": ChannelWrite(channels=["__end__"])
}
)
]
),
"tools": PregelNode(
bound=<原始工具执行函数>,
# 工具节点的触发器,现在精准监听动态路由发来的特定通道
triggers=["tools_trigger_channel"],
# 工具执行完后,把结果扔进 finish 通道,这又会反过来唤醒上面的 agent
writers=["tools_finish_channel"]
)
}
图构造流程
- 创建一个
StateGraph,使得整个运行结构定义为“状态机”,状态是一个具有一个键:messages的TypedDict
from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START
from langgraph.graph.message import add_messages
class State(TypedDict):
# 消息类型为列表。
# 使用 Reducer 约束器:operator.add 表示将新列表拼接到旧列表后面
# 注释中的 add_messages 用于指定该状态字段的更新方式:
# 这里表示**新消息会追加到列表末尾**,而不是覆盖原有消息。该函数可自定义
messages: Annotated[list, add_messages]
graph_builder = StateGraph(State)
- 定义工具
from langchain_tavily import TavilySearch
tool = TavilySearch(max_results=2)
tools = [tool]
- 创建一个调用工具的函数,包装在一个名为
BasicToolNode的新节点,该节点检查状态中的最新消息,如果消息包含tool_calls,则调用工具。
import json
from langchain_core.messages import ToolMessage
class BasicToolNode:
"""A node that runs the tools requested in the last AIMessage."""
def __init__(self, tools: list) -> None:
self.tools_by_name = {tool.name: tool for tool in tools}
def __call__(self, inputs: dict):
if messages := inputs.get("messages", []):
message = messages[-1]
else:
raise ValueError("No message found in input")
outputs = []
for tool_call in message.tool_calls:
tool_result = self.tools_by_name[tool_call["name"]].invoke(
tool_call["args"]
)
outputs.append(
ToolMessage(
content=json.dumps(tool_result),
name=tool_call["name"],
tool_call_id=tool_call["id"],
)
)
return {"messages": outputs}
tool_node = BasicToolNode(tools=[tool])
- 创建聊天体
## 创建聊天体,并作为节点加入图
llm = init_chat_model("openai:gpt-4.1")
llm_with_tools = llm.bind_tools(tools)
def chatbot(state: State):
return {"messages": [llm_with_tools.invoke(state["messages"])]}
- 创建节点
graph_builder.add_node("chatbot", chatbot)
graph_builder.add_node("tools", tool_node)
- 创建
route_tools路由函数,它检查聊天机器人输出中的tool_calls,决定下一个节点
def route_tools(
state: State,
):
"""
用于条件边。如果最后一条消息包含工具调用,则路由到 ToolNode;
否则路由到结束节点。
"""
if isinstance(state, list):
ai_message = state[-1]
elif messages := state.get("messages", []):
ai_message = messages[-1]
else:
raise ValueError(f"输入状态中未找到消息: {state}")
if hasattr(ai_message, "tool_calls") and len(ai_message.tool_calls) > 0:
return "tools_key"
return END
- 创建边
#### 1. 创建静态边
graph_builder.add_edge(START, "chatbot")
# 每当工具执行完毕后,都回到聊天机器人,由它决定下一步操作
graph_builder.add_edge("tools", "chatbot")
#### 2. 创建条件边
# tools_condition 函数:如果机器人需要调用工具则返回 "tools",如果可以直接回答则返回 END。
# 这个条件路由定义了智能体的主循环。
graph_builder.add_conditional_edges(
"chatbot",
route_tools,
# 下面的字典用于告诉图:如何将条件函数的输出映射到具体节点。默认是直接使用输出值。
# 但如果你想使用非 "tools" 命名的节点,可以修改字典的值,例如:"tools": "my_tools"
{"tools_key": "tools", END: END},
)
graph = graph_builder.compile()
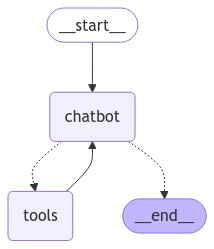
BasicToolNode 和 route_tools 都可以预构建,LangGrap 也提供
BasicToolNode替换为预构建的 ToolNoderoute_tools替换为预构建的 tools_condition
import os
from langchain.chat_models import init_chat_model
os.environ["OPENAI_API_KEY"] = "sk-..."
llm = init_chat_model("openai:gpt-4.1")
from typing import Annotated
from langchain_tavily import TavilySearch
from langchain_core.messages import BaseMessage
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
from langgraph.prebuilt import ToolNode, tools_condition
class State(TypedDict):
messages: Annotated[list, add_messages]
graph_builder = StateGraph(State)
tool = TavilySearch(max_results=2)
tools = [tool]
llm_with_tools = llm.bind_tools(tools)
def chatbot(state: State):
return {"messages": [llm_with_tools.invoke(state["messages"])]}
graph_builder.add_node("chatbot", chatbot)
# 直接声明为工具 Node
tool_node = ToolNode(tools=[tool])
graph_builder.add_node("tools", tool_node)
# 工具路由函数 直接变成 tools_condition
graph_builder.add_conditional_edges(
"chatbot",
tools_condition,
)
# Any time a tool is called, we return to the chatbot to decide the next step
graph_builder.add_edge("tools", "chatbot")
graph_builder.add_edge(START, "chatbot")
# 加入检查点
memory = MemorySaver()
graph = graph_builder.compile(checkpointer=memory)
子图
使用子图的一些原因是:
- 构建 多代理系统
- 当您想在多个图中重用一组节点时
- 当您希望不同团队独立处理图的不同部分时,您可以将每个部分定义为子图;只要子图接口(输入和输出模式)得到遵守,父图就可以在不了解子图任何细节的情况下构建。
添加子图时,需要定义父图和子图如何通信
- 共享状态模式— 父图和子图在其状态模式具有共享状态键
- 不同状态模式— 父图和子图的模式中没有共享状态键
- 每个图/代理保留私有消息历史。
在编译父图时提供检查器 checkpoint,LangGraph 会自动将检查器传播到子子图。如果希望子图拥有自己的内存,可以将子图编译为 with checkpointer=True。
记忆
LangGraph 通过持久性检查点解决了这个问题。如果您在编译图时提供一个 checkpointer,并在调用图时提供一个 thread_id,LangGraph 会在每一步之后自动保存状态。当您使用相同的 thread_id 再次调用图时,图会加载其保存的状态,允许聊天机器人从上次中断的地方继续。
我们稍后会看到,检查点比简单的聊天记忆功能强大得多——它允许您随时保存和恢复复杂状态,用于错误恢复、人工干预工作流、时间旅行交互等。但首先,让我们添加检查点以实现多轮对话。
短期记忆
短期记忆允许你的应用程序记住单个线程或对话中的先前交互。线程在一个会话中组织多个交互,类似于电子邮件将消息分组到单个对话中的方式。
LangGraph 将短期记忆作为代理状态的一部分进行管理,通过线程范围的检查点持久化。这种状态通常可以包括对话历史以及其他有状态数据,例如上传的文件、检索到的文档或生成的工件。通过将这些存储在图的状态中,机器人可以访问给定对话的完整上下文,同时保持不同线程之间的分离。
由于对话历史是表示短期记忆最常见的形式,在下一节中,我们将介绍在消息列表变得很长时管理对话历史的技术。
启用短期内存后,长对话可能会超出 LLM 的上下文窗口。常见的解决方案有:
- 修剪:删除前或后 N 条消息(在调用 LLM 之前)
- 摘要:总结历史中较早的消息并用摘要替换它们
- 从 LangGraph 状态永久删除消息
- 自定义策略(例如,消息过滤等)
这使得代理能够跟踪对话,而不会超出 LLM 的上下文窗口。
时间旅行
实际就是利用检查点
- 使用
invoke或streamAPI 通过初始输入运行图。 - 识别现有线程中的检查点:使用 get_state_history() 方法检索特定
thread_id的执行历史并找到所需的checkpoint_id。
或者,在您希望执行暂停的节点前设置一个断点。然后您可以找到在该断点之前记录的最新检查点。 - (可选)修改图状态:使用 update_state 方法在检查点修改图的状态,并从替代状态恢复执行。
- 从检查点恢复执行:使用
invoke或streamAPI,输入为None,配置中包含相应的thread_id和checkpoint_id。
长期记忆
LangGraph 将长期记忆作为 JSON 文档存储在存储中。每个记忆都组织在一个自定义的 namespace(类似于文件夹)和一个独特的 key(像文件名)之下。命名空间通常包括用户或组织 ID 或其他标签,以便于组织信息。这种结构实现了记忆的层次化组织。通过内容过滤器支持跨命名空间搜索。请参阅下面的示例。
from langgraph.store.memory import InMemoryStore
def embed(texts: list[str]) -> list[list[float]]:
# Replace with an actual embedding function or LangChain embeddings object
return [[1.0, 2.0] * len(texts)]
# InMemoryStore saves data to an in-memory dictionary. Use a DB-backed store in production use.
store = InMemoryStore(index={"embed": embed, "dims": 2})
user_id = "my-user"
application_context = "chitchat"
namespace = (user_id, application_context)
store.put(
namespace,
"a-memory",
{
"rules": [
"User likes short, direct language",
"User only speaks English & python",
],
"my-key": "my-value",
},
)
# get the "memory" by ID
item = store.get(namespace, "a-memory")
# search for "memories" within this namespace, filtering on content equivalence, sorted by vector similarity
items = store.search(
namespace, filter={"my-key": "my-value"}, query="language preferences"
)
长期记忆的思考框架
长期记忆是一个复杂的挑战,没有一劳永逸的解决方案。然而,以下问题提供了一个结构化框架,帮助你探索不同的技术
记忆的类型是什么?
人类利用记忆来记住 事实 Semantic_memory、经验 Episodic_memory 和 规则 Procedural_memory。AI 代理也可以以相同的方式使用记忆。例如,AI 代理可以使用记忆来记住关于用户的具体事实以完成任务。我们将在下面的部分中详细介绍几种记忆类型。
你希望何时更新记忆?
记忆可以作为代理应用程序逻辑的一部分进行更新(例如,“在热路径上”)。在这种情况下,代理通常在响应用户之前决定记住事实。或者,记忆可以作为后台任务进行更新(在后台/异步运行并生成记忆的逻辑)。我们将在下面的部分中解释这些方法之间的权衡。
不同的应用程序需要各种类型的记忆。尽管类比并不完美,但研究人类记忆类型可以提供深刻的见解。一些研究(例如,CoALA 论文。甚至将这些人类记忆类型映射到了 AI 代理中使用的类型。
| 记忆类型 | 存储内容 | 人类示例 | 代理示例 |
|---|---|---|---|
| 语义 | 事实 | 我在学校学到的东西 | 关于用户的事实 |
| 情景 | 经验 | 我做过的事情 | 代理过去的行动 |
| 程序 | 指令 | 本能或运动技能 | 代理系统提示 |
缓存
与 记忆的区别
记忆(checkpoint/State)和缓存(Cache)不能混为一谈。记忆是用来“记账(保存状态)”的,而节点缓存是用来“抄作业(免除重复计算)。
- Checkpoint 是“按轨迹寻址”(基于 Thread ID 和步数)
Checkpoint 的本质是一个 “游戏存档记录仪”。 当你启用 Checkpointer 时(比如传入 thread_id="user_123"),它的寻址逻辑是极其刻板且线性的:
- 它的记录方式:
[用户 user_123] -> [第 1 步:查订单] -> [第 2 步:退款计算结果是 50]。 - 它的使用场景: “断点续传”或“时间旅行”。如果图在第 2 步崩溃了,下次你传入同样的
thread_id="user_123"重试时,引擎会查 Checkpoint:“哦,user_123 的第 1 步已经跑过了,我直接从第 2 步开始”。
痛点来了:Checkpoint 无法跨轨迹(跨用户)复用! 如果此时另一个用户 thread_id="user_456" 也来问了完全一样的问题(触发了完全一样的订单退款计算),系统会去查 user_456 的 Checkpoint。显然,那里是一片空白。系统只能老老实实再算一遍。
因为 Checkpoint 认的是“这是谁的记录,这是哪一步”,它不关心计算的内容本身是不是重复的。
- Node Cache 是“按内容寻址”(基于输入参数的 Hash 值)
Node Cache 的本质是一个 “全局知识库”。 当你启用 cache_policy 时,它的寻址逻辑是横向打通的:
- 它的记录方式:
[输入参数 {"x": 5} 的 Hash 值] -> [结果 10]。是基于节点和输入生成缓存 Hash,这是记忆没有的。 - 它的使用场景: 只要任何时间、任何地点、任何用户,让这个节点执行了完全相同的输入,它直接秒回结果。
优势:它打破了 Thread ID 的隔离! 不管你是 user_123 还是 user_456,也不管这是第 1 步还是第 10 步,只要你们喂给这个耗时节点的数据都是 {"x": 5},缓存系统就会说:“不管你是谁的进度,这道题我算过,答案是 10。”
示例
import time
from typing_extensions import TypedDict
from langgraph.graph import StateGraph
from langgraph.cache.memory import InMemoryCache
from langgraph.types import CachePolicy
class State(TypedDict):
x: int
result: int
builder = StateGraph(State)
def expensive_node(state: State) -> dict[str, int]:
# expensive computation
time.sleep(2)
return {"result": state["x"] * 2}
builder.add_node("expensive_node", expensive_node, cache_policy=CachePolicy(ttl=3))
builder.set_entry_point("expensive_node")
builder.set_finish_point("expensive_node")
graph = builder.compile(cache=InMemoryCache())
print(graph.invoke({"x": 5}, stream_mode='updates'))
[{'expensive_node': {'result': 10}}]
## 用到缓存:参数相同
print(graph.invoke({"x": 5}, stream_mode='updates'))
[{'expensive_node': {'result': 10}, '__metadata__': {'cached': True}}]
多代理 Multi-Agent
官方文档:构建多智能体系统
一个代理是一个使用大型语言模型(LLM)来决定应用程序控制流的系统。随着这些系统的开发,它们可能会随着时间变得越来越复杂,从而更难管理和扩展。例如,你可能会遇到以下问题:
- 代理拥有的工具过多,在决定下一步调用哪个工具时做出糟糕的决策
- 上下文变得过于复杂,单个代理难以跟踪
- 系统需要多个专业领域(例如,规划师、研究员、数学专家等)
为了解决这些问题,可以考虑将应用程序分解成多个更小、独立的代理,并将它们组合成一个多代理系统。这些独立的代理可以像一个提示和一次 LLM 调用那样简单,也可以像一个 ReAct 代理那样复杂(甚至更复杂!)。
使用多代理系统的主要优点是:
- 模块化:分离的代理使开发、测试和维护代理系统变得更容易。
- 专业化:可以创建专注于特定领域的专家代理,这有助于提高整个系统的性能。
- 控制:可以明确控制代理如何通信(而不是依赖函数调用)。
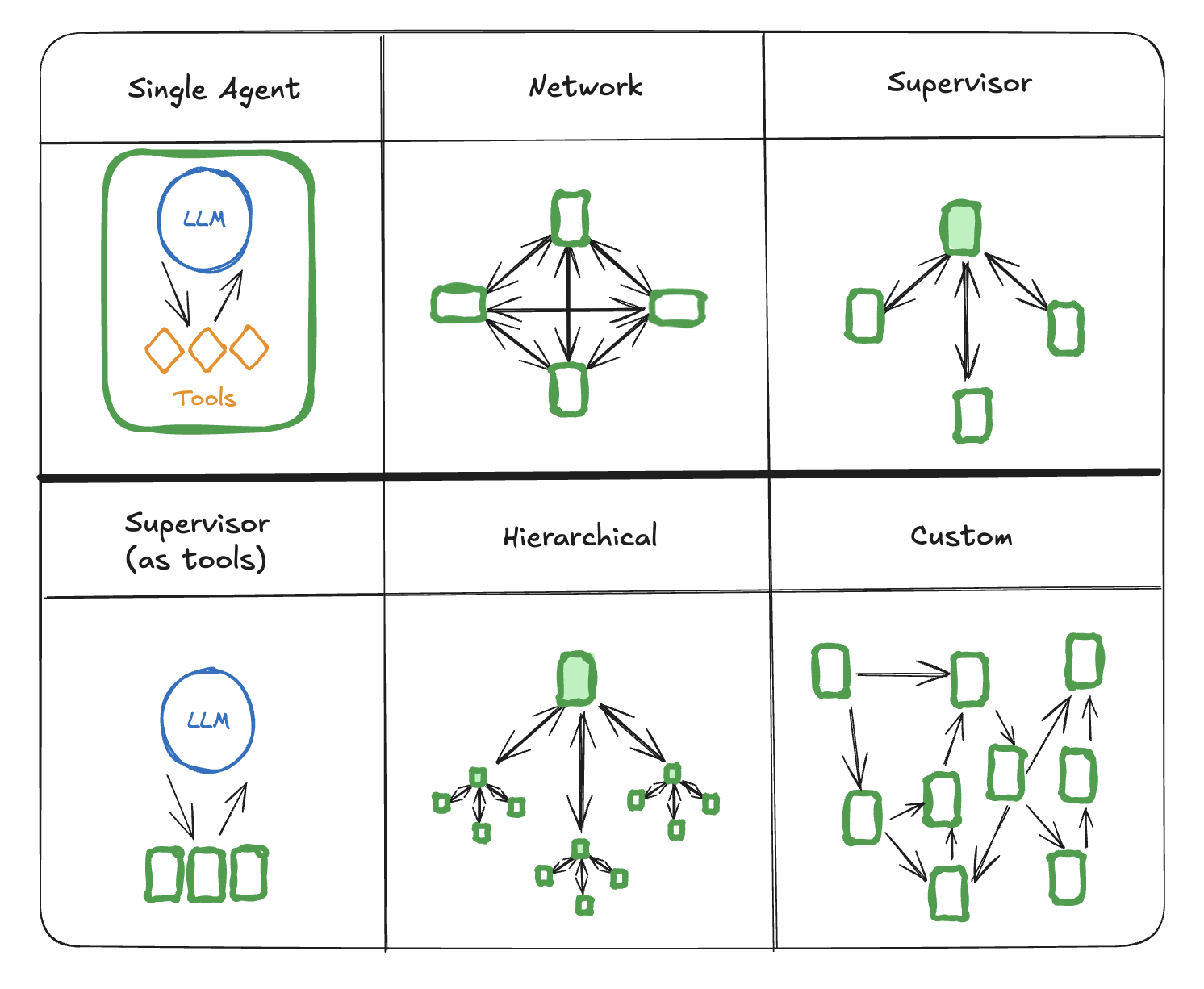
- 网络:每个代理都可以与 [有其他代理通信。任何代理都可以决定下一步调用哪个其他代理。
- 主管:每个代理都与一个主管代理通信。主管代理决定下一步应该调用哪个代理。
- 主管(工具调用):这是主管架构的一个特例。单个代理可以表示为工具。在这种情况下,主管代理使用一个支持工具调用的 LLM 来决定调用哪个代理工具,以及传递给这些代理的参数。
- 分层:你可以定义一个具有主管之主管的多代理系统。这是主管架构的泛化,允许更复杂的控制流。
- 自定义多代理工作流:每个代理只与部分代理通信。流程的部分是确定性的,并且只有某些代理可以决定下一步调用哪个其他代理。
LangGraph 中多代理协作(Multi-Agent Collaboration)经典实现方式是:Supervisor(监督者) + Worker Agents(工作者代理) 的分层多代理架构(Hierarchical Multi-Agent)。这种方式让一个 Supervisor 负责任务分解和路由,多个专业化子代理负责具体执行,协作完成复杂任务。
Supervisor 实现方式
这个示例实现一个研究 + 写作团队:
- Supervisor:分析任务,决定调用哪个子代理或结束
- Researcher:负责搜索和收集信息(带工具)
- Writer:负责将信息整理成最终报告
from typing import Annotated, Literal
from typing_extensions import TypedDict
from langchain_core.messages import BaseMessage, HumanMessage, AIMessage
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI # 或其他模型:ChatGroq, ChatAnthropic 等
from langgraph.graph import StateGraph, START, END
from langgraph.prebuilt import create_react_agent, ToolNode
from langgraph.prebuilt import tools_condition
# ------------------ 1. 定义共享状态 ------------------
class AgentState(TypedDict):
messages: Annotated[list[BaseMessage], "add_messages"] # 所有消息历史共享
next: str # Supervisor 决定下一个执行的代理("researcher", "writer", "FINISH")
# ------------------ 2. 创建工具(示例) ------------------
from langchain_community.tools import TavilySearchResults # 需要安装 tavily-python 并设置 API Key
search_tool = TavilySearchResults(max_results=3)
# ------------------ 3. 创建子代理(Worker Agents) ------------------
llm = ChatOpenAI(model="gpt-4o", temperature=0)
# Researcher Agent(研究代理)
research_agent = create_react_agent(
llm,
tools=[search_tool],
name="researcher",
prompt="You are a world-class researcher. Use search tools to gather accurate information."
)
# Writer Agent(写作代理)
writer_prompt = ChatPromptTemplate.from_messages([
("system", "You are an excellent technical writer. Summarize the research results into a clear, professional report."),
("placeholder", "{messages}")
])
writer_agent = create_react_agent(llm, tools=[], prompt=writer_prompt, name="writer")
# ------------------ 4. Supervisor(监督者) ------------------
supervisor_prompt = ChatPromptTemplate.from_messages([
("system", """You are a supervisor managing a team: researcher and writer.
Your job is to decide who should act next based on the current state.
- If more information is needed → send to "researcher"
- If information is sufficient → send to "writer"
- If the report is ready → respond with "FINISH"
Available agents: researcher, writer, FINISH"""),
("placeholder", "{messages}"),
])
def supervisor_node(state: AgentState) -> AgentState:
# 把历史消息传给 Supervisor LLM,让它决定下一步
response = llm.invoke(supervisor_prompt.format_messages(messages=state["messages"]))
# 解析决定(简单方式:让 LLM 输出 "next: researcher" 或使用 structured output)
next_agent = "researcher" # 这里实际应解析 LLM 输出,可用 Pydantic 输出解析器优化
if "writer" in response.content.lower():
next_agent = "writer"
elif "finish" in response.content.lower():
next_agent = "FINISH"
return {"next": next_agent}
# ------------------ 5. 构建 Graph ------------------
workflow = StateGraph(AgentState)
# 添加节点
workflow.add_node("researcher", research_agent)
workflow.add_node("writer", writer_agent)
workflow.add_node("supervisor", supervisor_node)
# 添加边
workflow.add_edge(START, "supervisor")
# 从 supervisor 条件路由
def route_supervisor(state: AgentState) -> Literal["researcher", "writer", END]:
next_agent = state.get("next", "FINISH")
if next_agent == "FINISH":
return END
return next_agent
workflow.add_conditional_edges("supervisor", route_supervisor)
# 子代理完成后返回 supervisor 继续协调
workflow.add_edge("researcher", "supervisor")
workflow.add_edge("writer", "supervisor")
# 编译应用
app = workflow.compile()
# ------------------ 6. 运行示例 ------------------
result = app.invoke({
"messages": [HumanMessage(content="研究一下 2026 年香港 AI 发展现状,并写一份 500 字的专业报告")]
})
print(result["messages"][-1].content) # 输出最终报告
LangChain 官方推出了 langgraph-supervisor 包,大幅简化了 Supervisor 的创建:
from langgraph_supervisor import create_supervisor
from langgraph.prebuilt import create_react_agent
# 创建子代理(同上)
researcher = create_react_agent(llm, [search_tool], name="researcher")
writer = create_react_agent(llm, [], name="writer")
# 一行创建 supervisor
supervisor = create_supervisor(
[researcher, writer],
model=llm,
prompt="You are a smart supervisor. Delegate tasks to researcher or writer. Finish when the report is complete."
)
app = supervisor.compile()
通信与状态管理
构建多代理系统时最重要的事情是弄清楚代理如何通信。代理之间通信的一种常见、通用的方式是通过消息列表。这引出了以下问题:
- 代理是通过交接还是工具调用进行通信?
- 哪些消息从一个代理传递到下一个代理?
- 在消息列表中如何表示交接?
- 你如何管理子代理的状态?
此外,如果你正在处理更复杂的代理或希望将单个代理状态与多代理系统状态分开,你可能需要使用不同的状态模式。
针对以上 4 个问题,对应以下答案
1. 状态传递的方式:交接 Handoff vs 工具调用 Tool Calling
在代理之间传递的“有效载荷”是什么?
在大多数架构中,代理通过交接进行通信,并将图状态作为交接有效载荷的一部分进行传递。具体来说,代理将消息列表作为图状态的一部分传递。在带有工具调用的主管的情况下,有效载荷是工具调用参数。
2. 状态传递的范围
代理之间最常见的通信方式是通过共享状态通道,通常是消息列表。这假设状态中总是有至少一个代理共享的通道(键)(例如,messages)。当通过共享消息列表进行通信时,还有一个额外的考虑:代理应该共享其思维过程的完整历史还是只共享最终结果?
这涉及 上下文污染(Context Pollution) 与 Token 优化 的博弈:
- 全量共享(Shared Global State): 依赖
add_messages等 Reducer 函数,将所有代理产生的消息追加到同一个全局messages列表中。下游代理获得完整历史,但易受无关中间推理过程的干扰。 - 过滤/摘要传递(State Pruning/Summarization): 在图的路由边缘节点(Edge Nodes)拦截状态,剔除(Filter)特定代理的私有思考(如
AIMessage的tool_calls内部流转),或调用摘要节点将历史压缩为结构化上下文,再传递给下一个代理。
代理之间最常见的通信方式是通过共享状态通道,通常是消息列表。这假设状态中总是有至少一个代理共享的通道(键)(例如,messages)。当通过共享消息列表进行通信时,还有一个额外的考虑:代理应该共享其思维过程的完整历史还是只共享最终结果?
- 共享完整思维
代理可以与所有其他代理共享其思维过程的完整历史(即,“草稿本”)。这个“草稿本”通常看起来像一个消息列表。共享完整思维过程的好处是,它可能帮助其他代理做出更好的决策,并提高整个系统的推理能力。缺点是,随着代理数量和复杂性的增长,“草稿本”将迅速增长,可能需要额外的内存管理策略。
- 只共享最终结果
代理可以拥有自己的私有“草稿本”,并且只与其余代理共享最终结果。这种方法可能更适用于具有许多代理或更复杂的代理的系统。在这种情况下,你需要定义具有不同状态模式的代理。
对于作为工具调用的代理,主管根据工具模式确定输入。此外,LangGraph 允许在运行时将状态传递给单个工具,因此下属代理可以在需要时访问父状态。
- 在消息中指示代理名称
在消息中指示特定 AI 消息来自哪个代理会很有帮助,特别是对于冗长的消息历史。一些 LLM 提供商(如 OpenAI)支持向消息添加 name 参数——你可以使用它将代理名称附加到消息中。如果不支持,你可以考虑手动将代理名称注入到消息内容中,例如,
3. 交接的标识:在消息列表中如何表示交接?
交接通常是通过 LLM 调用专用的交接工具来完成。这代表着带有工具调用的 AI 消息,被传递给下一个代理(LLM)。然而大多数 LLM 提供商不支持接收带有工具调用的 AI 消息,导致没有相应的工具消息。因此有两种选择:
- 在消息列表中添加额外的工具消息,例如,“已成功转移到代理 X”。例如:向
messages列表末尾追加一条ToolMessage(content="Successfully transferred to Agent B", name="transfer_to_b")。 - 移除带有工具调用的 AI 消息
实际上,大多数开发者选择选项 (1)。
4. 状态封装:如何管理子代理的状态?
一种常见的做法是让多个代理在共享消息列表上通信,但只将它们的最终消息添加到列表中。这意味着任何中间消息(例如,工具调用)都不会保存在此列表中。
如果你确实想保存这些消息,以便如果将来调用此特定子代理,你可以将这些消息传回,该怎么办?有两种高级方法可以实现这一点:
- 将这些消息存储在共享消息列表中,但在将列表传递给子代理 LLM 之前对其进行过滤。例如,你可以选择过滤掉来自其他代理的所有工具调用。
- 在子代理的图状态中为每个代理存储一个单独的消息列表(例如,alice_messages)。这将是它们对消息历史的“视图”。
5. 模式隔离:分离单代理与多代理系统状态
一个代理可能需要与其余代理有不同的状态模式。例如,一个搜索代理可能只需要跟踪查询和检索到的文档。核心思想是状态空间解耦(State Schema Isolation):
- 通道映射(Channel Mapping): 父图与子图分别定义不同的
TypedDict状态模式。 - 交集同步: 父图(多代理级)只维护全局变量(如
messages,global_plan)。 - 私有隔离: 子代理(单代理级)的
State可以包含大量私有字段(如scratchpad,current_tool_retries)。当子图结束执行并向上层返回时,LangGraph 引擎仅根据状态键的交集(如只提取更新后的messages)同步回父图,从而防止局部中间变量污染全局状态。
Human in the loop
主要功能
- 持久化执行状态:LangGraph 在每个步骤后都会检查图状态,允许在定义好的节点处无限期地暂停执行。这支持异步的人工审查或输入,不受时间限制。
- 灵活的集成点:HIL 逻辑可以在工作流的任何点引入。这允许有针对性的人工参与,例如批准 API 调用、更正输出或引导对话。
典型用例
- 审查工具调用:在工具执行之前,人工可以审查、编辑或批准 LLM 请求的工具调用。
- 比如“文案修改”、“信息补全”或“条件报警”。大模型发现用户输入的表单少了一个必填字段(比如没填身份证号),大模型在解析节点内直接
value = interrupt("请补充身份证号"),拿到身份证号后再继续执行。
- 比如“文案修改”、“信息补全”或“条件报警”。大模型发现用户输入的表单少了一个必填字段(比如没填身份证号),大模型在解析节点内直接
- 验证 LLM 输出:人工可以审查、编辑或批准 LLM 生成的内容。
- 提供上下文:使 LLM 能够明确请求人工输入以进行澄清或提供额外细节,或支持多轮对话。
实现
interrupt函数:在特定点暂停执行,并显示信息供人工审查。Command原语:用于使用人工提供的值恢复执行。
示例(如果节点里有多个 interrupt() 调用,LangGraph 会按顺序匹配 resume 值列表)
from langgraph.types import interrupt, Command
# 节点:人工审核与修改
# 1. 底层机制:interrupt() 会抛出中断异常,终止当前线程,并将当前图的状态(State)序列化并持久化至 Checkpointer。
# 2. 重入执行(Re-execution):当系统收到恢复指令时,调度器会拉起新线程,从本节点第一行代码【重新执行】。
# 3. 幂等性约束:务必确保 interrupt() 语句上方的代码是幂等的。严禁在此处放置外部 API 调用、写库等具有副作用的操作,以防重复执行。
def human_node(state: State):
# 【注意】节点恢复执行时,依然会从此处开始。
# 执行流转:
# - 初次调用:抛出异常,当前栈帧销毁,程序挂起。字典 payload 返回给外部系统。
# - 恢复调用:引擎拦截内部调用,读取传入的 resume 数据并赋值给 value,程序继续向下执行。
value = interrupt(
{
"text_to_revise": state["some_text"]
}
)
# 仅在【恢复调用】阶段,代码才会执行到此处并返回更新后的状态
return {
"some_text": value
}
# 必须配置 checkpointer 以支持执行状态的持久化与恢复
graph = graph_builder.compile(checkpointer=checkpointer)
# =========================================================
# 阶段 1:挂起执行(请求人工介入)
# =========================================================
# 声明 thread_id 开启持久化会话追踪
config = {"configurable": {"thread_id": "some_id"}}
# 初次调用。引擎遇到 interrupt() 后终止执行并立即返回。图处于挂起状态。
result = graph.invoke({"some_text": "original text"}, config=config)
# 输出中断状态对象,获取需透传给外部业务层(如前端 GUI)的上下文信息
print(result['__interrupt__'])
# > [
# > Interrupt(
# > value={'text_to_revise': 'original text'}, # 抛出的业务 Payload
# > resumable=True, # 标识该挂起状态支持恢复操作
# > ns=['human_node:6ce9e64f...'] # 调度引擎追踪节点任务的 Namespace ID
# > )
# > ]
# =========================================================
# 阶段 2:状态注入与恢复执行
# =========================================================
# 模拟外部业务层收到人工修改结果后,下达恢复调度指令。
# 引擎恢复逻辑:
# 1. 根据 thread_id 从 Checkpointer 反序列化提取快照。
# 2. 重新启动并执行 human_node。
# 3. 当再次命中 interrupt() 时,将 resume 参数注入并绕过异常抛出。
# 4. 返回最新 State,图继续执行后续拓扑逻辑。
print(graph.invoke(Command(resume="Edited text"), config=config))
# > {'some_text': 'Edited text'}
命令
Send
默认情况下,Nodes 和 Edges 是预先定义的,并在同一个共享状态上操作。然而,在某些情况下,确切的边可能无法预先知道,或者您可能希望同时存在不同版本的 State。一个常见的例子是 map-reduce 设计模式。在此设计模式中,第一个节点可能会生成一个对象列表,您可能希望将某些其他节点应用于所有这些对象。对象的数量可能无法预先知道(这意味着边的数量可能无法知道),并且下游 Node 的输入 State 应该不同(每个生成的对象对应一个)。
为了支持这种设计模式,LangGraph 支持从条件边返回 Send 对象。Send 接受两个参数:第一个是节点名称,第二个是要传递给该节点的状态。
def continue_to_jokes(state: OverallState):
return [Send("generate_joke", {"subject": s}) for s in state['subjects']]
graph.add_conditional_edges("node_a", continue_to_jokes)

Command
将控制流(边)和状态更新(节点)结合起来会很有用。例如,您可能希望在同一个节点中既执行状态更新又决定下一个要去的节点。LangGraph 提供了一种通过从节点函数返回 Command 对象来实现此目的的方法:
def my_node(state: State) -> Command[Literal["my_other_node"]]:
return Command(
# state update
update={"foo": "bar"},
# control flow
goto="my_other_node"
)
使用 Command,您还可以实现动态控制流行为(与条件边相同)。
def my_node(state: State) -> Command[Literal["my_other_node"]]:
if state["foo"] == "bar":
return Command(update={"foo": "baz"}, goto="my_other_node")
声明式 API
@entrypoint– 将函数标记为工作流的起始点,封装逻辑并管理执行流,包括处理长时间运行的任务和中断。@task– 表示一个离散的工作单元,例如 API 调用或数据处理步骤,可以在入口点内异步执行。任务返回一个类似 future 的对象,该对象可以被等待或同步解析。
@entrypoint
假设你要写一个非常简单的 Agent:“接收用户问题 -> 搜索一下维基百科 -> 让大模型总结回答”。这是一个纯线性的流(A -> B -> C),完全不需要复杂的循环或条件判断。
如果用 StateGraph 来写,你需要写大量的样板代码。明是一个可以用两行 Python 代码写完的线性逻辑,为了塞进图架构,你被迫:
- 发明了一个没必要的
State类。 - 把连贯的逻辑强行切成了好几个碎裂的函数。
- 写了一堆
add_node和add_edge的组装代码。
@entrypoint 的出现,就是为了让你能够像写普通 Python 函数一样写线性工作流,同时依然能白嫖 LangGraph 底层的 Checkpointer(记忆持久化)和时间旅行功能!
task
在纯线性或简单的脚本中,你确实可以只用一个 @entrypoint 把所有 Python 原生代码包起来。但当你的代码变长、涉及多个大模型调用时,直接写原生 Python 函数会暴露几个致命缺陷,这正是 @task 要解决的问题。
为什么需要
@task?(三大核心价值)
- 细粒度的状态恢复(防止重复消耗 Token)
假设你的 @entrypoint 里包含三个步骤:A(查资料,耗时 10 秒)-> B(写草稿,耗时 20 秒)-> C(发邮件,报错了)。
- 如果不加
@task: 当你修复了发邮件的 Bug 并重新运行这个线程(Thread)时,系统会把 A 和 B 重新执行一遍,白白浪费 30 秒和大量 Token。 - 如果 A 和 B 加了
@task: LangGraph 的 Checkpointer 会为每一个 task 记录独立的存档。重新运行时,系统发现 A 和 B 已经成功过了,会直接从缓存中读取结果,瞬间跳过,直接执行 C。
- 并行执行(Concurrency)
原生的 Python 循环通常是串行的。被 @task 装饰的函数被赋予了图计算引擎的调度能力,可以极其方便地触发高并发执行,特别适合“多路召回”或“批量处理”场景。
- 结构化追踪(LangSmith Observability)
在 LangSmith 的控制台中,如果不加 @task,整个 @entrypoint 只会显示为一个巨大的、不透明的执行块。加上 @task 后,每一个任务都会作为独立的图节点(Node)被清晰地监控其输入、输出、耗时和报错堆栈。
使用场景
- 检查点:当您需要将长时间运行操作的结果保存到检查点时,这样在恢复工作流时就不需要重新计算它。
- HLTL:如果您正在构建需要人工干预的工作流,则必须使用任务来封装任何随机性(例如 API 调用),以确保工作流可以正确恢复。
- 并行执行:对于 I/O 密集型任务,任务支持并行执行,允许多个操作并发运行而不会阻塞(例如,调用多个 API)。
- 可观测性:将操作封装在任务中,提供了一种使用 LangSmith 跟踪工作流进度和监控单个操作执行的方法。
- 可重试工作:当工作需要重试以处理故障或不一致时,任务提供了一种封装和管理重试逻辑的方法。
三大属性
当你使用函数 API 时,你需要完成一次思维的转变:不要把它当成一个普通的本地 Python 函数,而要把它当成一个随时会被挂起、会被跨机器转移、会被无情重试的“独立微服务”。 设计时需要考虑以下内容:
- 序列化:保证了数据能被搬运和保存。
- 确定性:保证了它不会在“时间旅行”和“重播”时精神分裂。(关注执行过程)
- 幂等性:保证了它在被反复重试时不会造成破坏。(关注执行结果)
函数式 API 与图 API 对比
函数式 API 和图 API (StateGraph) 提供了两种不同的范式来使用 LangGraph 创建应用程序。以下是一些主要区别:
- 控制流:函数式 API 不需要考虑图结构。您可以使用标准 Python 构造来定义工作流。这通常会减少您需要编写的代码量。
- 短期记忆:图 API 需要声明一个 State,并且可能需要定义 reducer 来管理图状态的更新。@entrypoint 和 @tasks 不需要显式状态管理,因为它们的状态作用域限定在函数内部,并且不跨函数共享。
- 检查点:两种 API 都生成和使用检查点。在图 API 中,每个超步后都会生成一个新的检查点。在函数式 API 中,当任务执行时,它们的結果會保存到与给定入口点关联的现有检查点中,而不是创建新的检查点。
- 可视化:图 API 可以轻松地将工作流可视化为图,这对于调试、理解工作流和与他人共享非常有用。函数式 API 不支持可视化,因为图是在运行时动态生成的。
图迁移
分为了两类:修改流程图结构(拓扑) 和 修改全局字典(状态)。
不管哪一类,在带状态(Memory)的 Agent 系统中进行版本迭代时,必须要遵循 “只增不减,向后兼容” 的原则:
- 如果你要改动流程(图节点),宁可新增节点,不要去删除老节点(可以把老节点的内容清空,直接 return 绕过它,但要保留它的名字当个空壳,以防老线程踩坑)。
- 如果你要改动数据格式(State),宁可新增一个 Key,不要去重命名旧的 Key。
- 反序列化灾难。如果你的 1.0 版本里
history字段是单纯的str,但在 2.0 代码里你改成了list[dict]。当引擎从 SQLite 数据库里读出老 Checkpoint,试图把它塞进新版的State类型里时,Python 强大的类型校验或者 Reducer 函数(比如add_messages)就会报类型错误(Type Error)。
- 反序列化灾难。如果你的 1.0 版本里
- 如果非要进行伤筋动骨的“不兼容修改”,最安全的做法是:废弃旧的
thread_id,让老用户重新开一局对话。
常见问题
LangGraph 会过时吗?
1. 技术会过时
目前 AI 这个以“天”为迭代单位的领域,它过时的速度可能会比你想象的还要快。 在 AI 圈有一句玩笑话:“AI 框架的保质期比牛奶还短。” 任何试图将快速发展的大语言模型(LLM)能力进行过度封装的工具,都面临着随时被底层模型升级“降维打击”的风险。
为什么 LangGraph 注定会被替代或重构?
- 大模型正在“吞噬”框架(模型能力内化): 我们现在之所以需要 LangGraph,是因为当前的大模型在执行长逻辑链、复杂规划和状态记忆时,经常会“幻觉”或“跑偏”。我们需要用一个死板的“图(Graph)”结构把它框起来。如果未来的模型原生具备了完美的复杂任务拆解、记忆管理和工具调度能力,那么像 LangGraph 这样复杂的外部脚手架就会变得多余。
- 过度工程化(Over-engineering)的诅咒: LangChain 整个生态一直饱受开发者诟病的一点就是“过度封装”和“学习曲线陡峭”。为了抽象出通用的概念,它引入了大量复杂的类和协议。许多资深开发者发现,写几百行纯 Python 的
while循环、if/else判断和原生的状态字典,往往比阅读 LangGraph 晦涩的文档、处理它奇怪的报错要高效且易于调试得多。 - 激烈的生态竞争: 市场上永远不缺挑战者。微软的 AutoGen、LlamaIndex 新推出的 Workflows、或者是像 OpenAI 和各大云厂商直接推出的底层 Agent/Assistants API,都在试图定义“如何构建智能体”的标准。如果哪天某个官方 API 提供了一套极其简单优雅的状态管理机制,LangGraph 的生存空间就会被严重压缩。
2. 思想不过时
即便几年后 LangGraph 的代码库被废弃,以下这些被它发扬光大的理念依然是构建复杂 AI 系统的基石:
- 状态机思维(State Machines): 用一个全局的“黑板(State)”来记录智能体执行到哪一步了,包含了什么上下文。
- 基于图的控制流(Graph-based Routing): 用节点(Nodes)隔离不同的逻辑处理,用条件边(Conditional Edges)做动态路由,并允许“回退重试(循环)”。
- 人机协同(Human-in-the-loop): 在关键节点(比如执行转账、发送全员邮件前)中断图的执行,等待人类审批后再继续。这是企业级 AI 落地永远的刚需。
Chain/Graph/Pipeline/Workflow
Chain(链 / LCEL)
- 含义:LangChain 最基础、最早的概念。把多个组件(Prompt、LLM、Tool、Retriever、Parser 等)串联起来,形成一个可执行的单元。
- 特点:
- 使用 LCEL(LangChain Expression Language) 语法,如 prompt | llm | parser。
- 本质上是 Directed Acyclic Graph (DAG) —— 有向无环图:可以有分支(branch),但不能有循环(不能回头)。
- 状态传递较弱,主要靠输入输出逐级传递。
- 例子:
chain = prompt_template | llm | output_parser result = chain.invoke({"question": "今天香港天气?"}) - 形象比喻:一条锁链或传送带,每个环节把输出交给下一个环节。
- 适用场景:快速原型、线性 RAG、结构化提取、简单问答等。
Graph
DAG(有向无环图)本身就是 Graph(图)的一种特例。
- 含义:用 节点(Nodes) + 边(Edges) + 状态(State) 来建模流程。
- Node:一个执行单元(可以是 LLM 调用、Tool 执行、自定义函数、甚至另一个子图)。
- Edge:节点之间的连接(普通边或条件边)。
- State:共享的持久化状态,所有节点都可以读写(支持 checkpoint 持久化)。
- 特点:
- 支持 循环(Cycles):可以反复执行某个节点(例如 Agent 反复调用工具直到满意)。
- 支持 动态路由:根据当前状态决定下一步去哪里(conditional edges)。
- 支持 分支、并行、多代理协作、human-in-the-loop、中断恢复等。
- 本质上是有状态的状态机(State Machine)。
- 形象比喻:一张地图或交通网络。你可以根据路况(当前状态)选择不同路径,甚至绕回来重走某段路。
Pipeline(管道)
- 含义:像工厂流水线一样,数据从一端输入,按固定顺序一步步处理,最终从另一端输出。
- 特点:线性(Linear)、顺序执行(sequential)、通常是单向流动。
- 对应关系:常用来描述 LangChain 中的整体执行流程,尤其在简单场景下。
- 例子:
- 用户查询 → 检索文档 → 总结 → 生成答案
- 这就是一个典型的 RAG Pipeline。
- 形象比喻:水管,一端进水,中间过滤、加热,最后出热水。路径固定,不能回头。
- 适用场景:简单、确定性的任务,步骤不会变化。
Workflow(工作流)
- 含义:对整个业务流程的统称。可以是线性的,也可以是复杂的。
- 在 LangChain/LangGraph 中的定位:
- LangChain:Workflow 通常用 Chain 或 Runnable 来实现,偏线性。
- LangGraph:Workflow 用 Graph 来实现,支持更复杂的编排。
- 特点:更偏向“业务视角”,强调步骤的整体安排、条件判断、并行等。
- 形象比喻:公司里的工作流程(审批流程、内容生产流程),可能有分支、审批、并行处理。
- 注意:Workflow 是一个广义概念,Chain 和 Graph 都是实现 Workflow 的具体方式。