文本向量化
BOW
把文本看作 “一堆词的集合”,只统计词的出现频率,完全忽略词的顺序、语法、语义。CountVectorizer(纯词频)、TfidfVectorizer(带权重的词频)都属于 BOW 体系。
创建 BOW 的步骤:
- 第一步,将文本分词成句子。
- 第一步中分词的句子又进一步分词了单词。
- 删除所有停用词或标点符号。
- 将所有单词转换为小写。
- 创建词语的频率分布图。
TF
为了更好地理解文本向量化的基础逻辑,我们可以结合词袋模型(BOW)的例子辅助理解(词袋模型是早期的文本向量化方法,常被用作基础对比):
假设我们有 4 条灾难相关的推文文本:
- ‘kind true sadly’
- ‘swear jam set world ablaze’
- ‘swear true car accident’
- ‘car sadly car caught up fire’
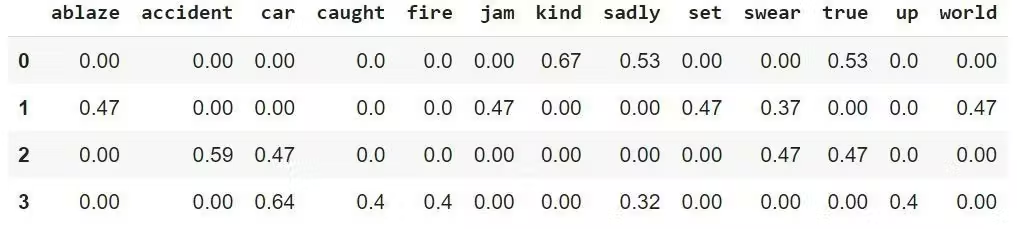
我们可以用 scikit-learn 中的 CountVectorizer 工具实现词袋模型:它会自动对文本进行分词、构建全局词汇表,再将每条文本转换为 “词频向量”—— 向量的每一位对应词汇表中的一个词,值则是该词在当前文本中的出现次数。

最终输出的词频矩阵结构为:
- 行:对应每条文档(这里是 4 条推文);
- 列:对应全局词汇表中的所有唯一词;
- 值:对应词在当前文档中的出现次数。
所以,词袋模型的本质是构建全局词汇表 → 把每条文本映射为 “词频向量”。
类似地,我们可以将 CountVectorizer 应用到更大规模的训练数据(比如 11370 条推文),得到对应的词频矩阵,再结合目标变量训练后续的机器学习 / 深度学习模型。(CountVectorizer 处理后的词频矩阵是模型的 “输入特征”,目标变量是模型的 “学习目标”,二者结合才能完成分类 / 回归任务)
TF-IDF
TF-IDF 词频 - 逆文档频率,基于统计方法,用于查找文本中词语的相关性,文本可以是单个文档,也可以是称为语料库的各种文档。一个词在当前文档中出现得越频繁(TF 高),且在所有文档中出现得越稀少(IDF 高),这个词对当前文档的重要性 / 代表性就越高。
TF-IDF 算法可应用于解决较为简单的自然语言处理和机器学习问题,例如信息检索、停用词去除、关键词提取和基础文本分析。然而,它无法有效地捕捉词序列中的语义含义。
为了创建 TF-IDF 向量,可以使用 Scikit-learn 的 TF-IDF Vectorizer(TfidfVectorizer)。行代表每个文档,列代表词汇表,tf-idf(i,j) 的值通过上述公式计算得出。所得矩阵可与目标变量一起用于训练机器学习/深度学习模型。
词袋模型与 TF-IDF 面临的挑战
在词袋模型(BOW)中,向量的维度等于词汇表的规模 —— 若向量中大部分元素为 0,最终会形成一个稀疏矩阵。这种稀疏性会从计算效率和信息利用两方面,增加模型构建的难度。
此外,词袋模型还有两个核心缺陷:一是无法体现词与词之间的语义关联,二是完全忽略词的顺序。这些问题也让后续的词嵌入技术面临更多挑战,具体表现为:
- 参数规模过大:高维的输入向量会导致神经网络需要学习的权重参数数量剧增;
- 语义与语序缺失:既无法捕捉词之间的关联,也不考虑词在文本中的出现顺序;
- 计算成本高昂:参数规模越大,模型的训练与推理过程会消耗更多计算资源。
而 TF-IDF 模型虽然能区分词的重要程度,但并没有解决 “高维稀疏” 的核心问题;同时和词袋模型一样,它也无法捕捉词之间的语义相似性。
Word2Vec
Word2Vec 是谷歌于 2013 年提出的技术,如今已成为解决各类高级自然语言处理(NLP)任务的基础工具之一,其核心作用是训练词嵌入(Word Embedding),而技术底层则基于 “分布假设”。
在这一假设的框架下,Word2Vec 提供了两种实现模型:跳字模型(Skip-gram)与连续词袋模型(CBOW)。
这两种模型本质上是结构简单的浅层神经网络,仅包含输入层、输出层与投影层。它们的核心逻辑是:通过捕捉文本中 “历史与未来的词序信息”,来还原词语所处的语言上下文。
具体训练过程中,模型会迭代遍历大规模文本语料库,学习词语之间的关联关系 —— 其核心假设是:文本中相邻出现的词语,往往具有语义相似性。借助这一特性,Word2Vec 能将语义相近的词语,映射到向量空间中距离较近的嵌入向量上。
在衡量词向量的语义相似度时,Word2Vec 通常采用余弦相似度作为度量指标。余弦相似度的取值等于两个词(或文档)向量之间夹角的余弦值,其含义可简单理解为:
- 若余弦值为 1,说明两个词语的向量完全重合,语义高度一致;
- 若夹角为 90°(余弦值为 0),则说明两个词语在上下文语义上没有关联,彼此独立。
简言之,Word2Vec 的核心价值,就是让语义相似的词语,拥有相似的向量表示。
CBOW
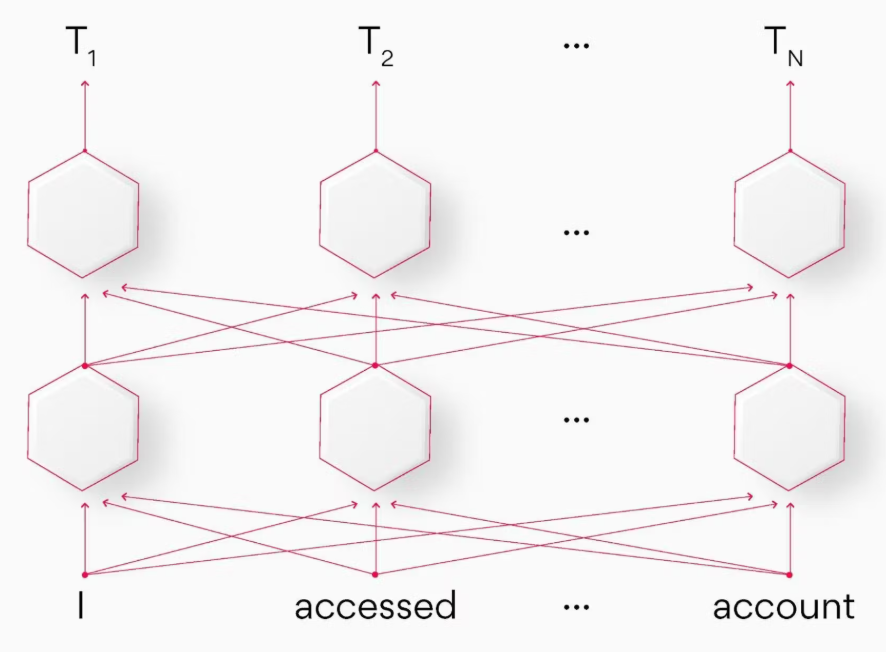
词嵌入/连续词袋模型(CBOW)的核心逻辑是:通过多个上下文词作为输入,让神经网络预测中间的目标词。
CBOW 的优势是训练速度快,尤其适合为高频词学习更精准的向量表示。我们可以结合 “窗口大小” 的概念,理解 CBOW 中 “上下文” 与 “当前词” 的关系:

在 CBOW 算法中,我们会设定一个 “窗口大小”(如图中窗口大小为 5):窗口中间的词是 “当前词”,其周围(包含前后)的词则构成 “上下文”。CBOW 的任务就是利用这些上下文词,预测出中间的当前词。
具体处理时,每个词会先通过独热编码 (One Hot Encoding) 映射到词汇表对应的编码向量,再输入 CBOW 神经网络。
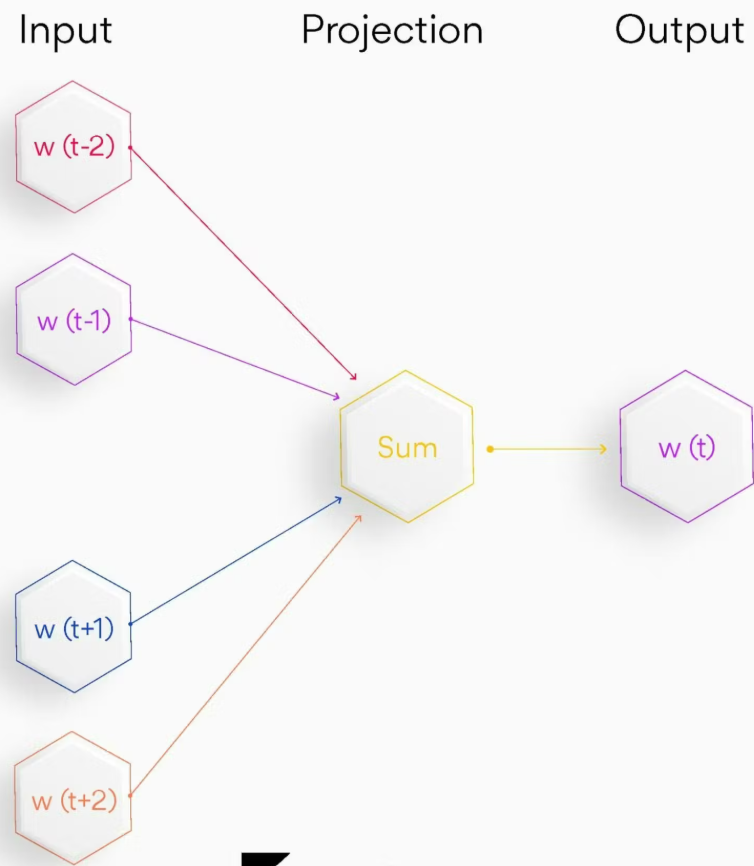
CBOW 的网络结构非常简洁:
- 输入层:接收上下文词的独热编码向量;
- 投影层:将所有上下文词的向量做求和(或平均)处理;
- 输出层:基于词汇表,输出 “当前词” 的概率分布(即预测当前词是什么)。 其中,投影层本质是一个全连接的密集层,负责将输入的上下文信息整合后传递给输出层。
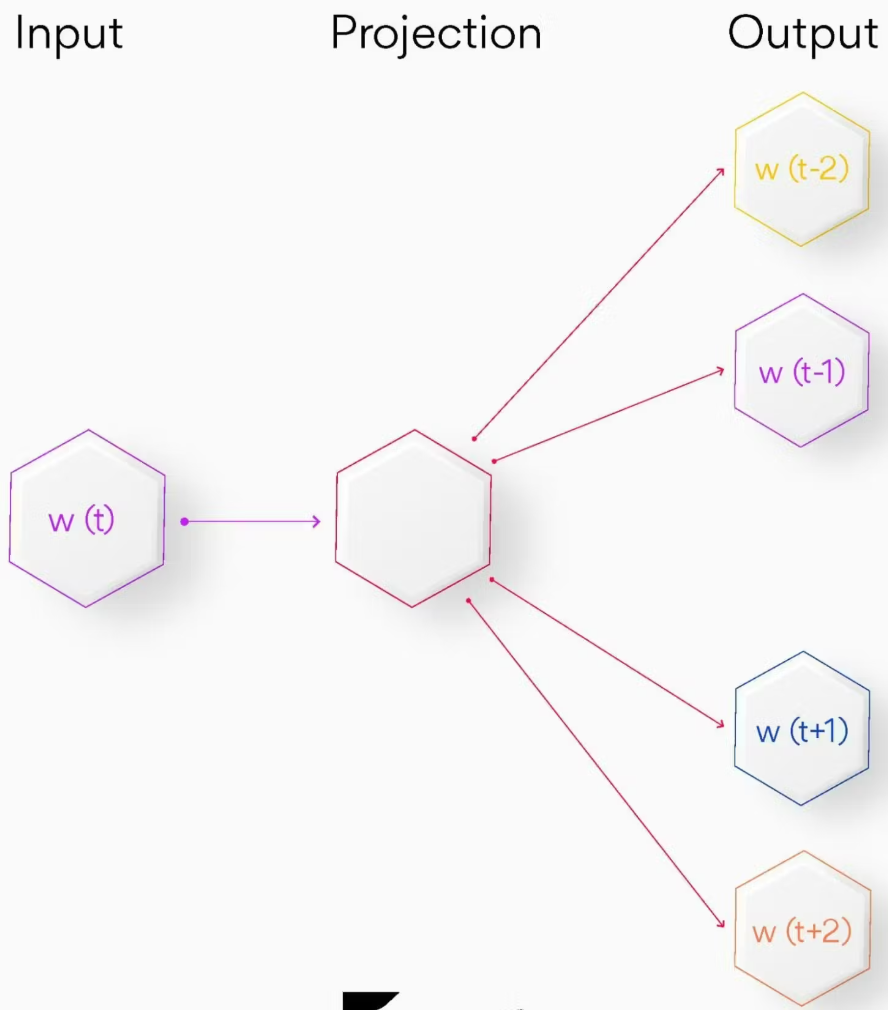
Skip-gram
一种与 CBOW 略有不同的词嵌入技术,因为它不基于上下文预测当前词。相反,它将每个当前词作为输入,输入到一个对数线性分类器和一个连续投影层中。这样,它就能预测当前词前后一定范围内的词。
这种变体仅以一个词作为输入,然后预测与其密切相关的上下文词。这就是它能够高效表示罕见词的原因。
代码演示
Word2Vec 的两种核心变体(跳字模型与连续词袋模型),最终目标都是学习模型隐藏层的权重参数 —— 而隐藏层的输出结果,就是我们需要的词嵌入向量。
接下来,我们通过代码演示如何用 Word2Vec 构建自定义词嵌入。
- 依赖库
Import Libraries
from gensim.models import Word2Vec
import nltk
import re
from nltk.corpus import stopwords
- 文本预处理 Word2Vec 的输入需要是 “已分词的文本语料”,因此我们先对原始文本做预处理:
#Word2Vec inputs a corpus of documents split into constituent words.
corpus = []
for i in range(0,len(X)):
tweet = re.sub(“[^a-zA-Z]”,” “,X[i])
tweet = tweet.lower()
tweet = tweet.split()
corpus.append(tweet)
训练完成后,我们可以通过 “查找相似词” 来验证词嵌入的效果(相似词的向量距离更近):
# 查找与“disaster(灾难)”语义最相似的词
model.wv.most_similar('disaster')
执行上述代码后,会得到与 “disaster” 相似的词列表(包含词与对应的相似度):
[
('alert', 0.9997072219848633),
('military', 0.999704270553589),
('murder', 0.9996907501220703),
('ash', 0.9996492862701416),
('base', 0.9996055364687655),
('oil', 0.9996046423912048),
('along', 0.99959397315979),
('based', 0.9995934963226318),
('inundation', 0.9995468854904175),
('west', 0.9995380640029907)
]
以 “灾难” 对应的词嵌入向量为例,其输出是一个 100 维的稠密向量(维度由模型训练时的 vector_size 参数指定):
array([-0.5968882, -0.33868956, -0.32643065, ..., 0.68051434, 0.7790246, 0.5617202], dtype=float32)
- 完整代码
# ===================== 第一步:导入依赖库 =====================
from gensim.models import Word2Vec
import nltk
import re
import pandas as pd
from nltk.corpus import stopwords
# 下载nltk停用词(首次运行需要,后续可注释)
nltk.download('stopwords')
# ===================== 第二步:准备指定的示例数据 =====================
# 替换为你指定的4条文本
data = {
"text": [
'kind true sadly',
'swear jam set world ablaze',
'swear true car accident',
'car sadly car caught up fire'
],
"label": [0, 0, 1, 1] # 模拟标签:0=非灾难,1=灾难相关(仅示例)
}
df = pd.DataFrame(data)
X = df["text"].values # 文本数据
y = df["label"].values # 目标变量(训练Word2Vec无需标签,仅用于后续参考)
# ===================== 第三步:文本预处理 =====================
# 初始化停用词表(英文)
stop_words = set(stopwords.words('english'))
corpus = [] # 存储预处理后的分词语料
for i in range(len(X)):
# 1. 移除非字母字符(保留空格)
tweet = re.sub("[^a-zA-Z]", " ", X[i])
# 2. 统一转为小写
tweet = tweet.lower()
# 3. 按空格分词
tweet = tweet.split()
# 4. 过滤停用词(当前示例无停用词,可保留逻辑)
tweet = [word for word in tweet if not word in stop_words]
# 5. 加入语料库
corpus.append(tweet)
# 打印预处理结果,验证效果
print("=== 预处理后的分词语料 ===")
for i, doc in enumerate(corpus):
print(f"文本{i+1}:{doc}")
# ===================== 第四步:训练Word2Vec模型 =====================
# 初始化并训练Word2Vec
model = Word2Vec(
sentences=corpus, # 输入语料(分词后的列表)
vector_size=100, # 词嵌入向量维度
window=3, # 适配短文本,缩小窗口大小(原5→3)
min_count=1, # 最小词频:保留所有词(示例文本词频低)
sg=0, # 模型类型:0=CBOW,1=Skip-gram
hs=0, # 分层softmax:0=关闭
negative=5, # 负采样数量
workers=4, # 线程数
epochs=100 # 训练轮数
)
# 保存模型(可选)
model.save("custom_word2vec.model")
# ===================== 第五步:验证词嵌入效果 =====================
print("\n=== 词嵌入效果验证 ===")
# 1. 查找与"accident"(事故)语义相似的词
similar_words = model.wv.most_similar('accident', topn=5)
print(f"\n与'accident'最相似的词:")
for word, similarity in similar_words:
print(f" {word}: {similarity:.4f}")
# 2. 获取单个词的嵌入向量(如"fire")
print(f"\n'fire'的词嵌入向量(前10维):")
fire_vec = model.wv["fire"]
print(fire_vec[:10]) # 打印前10维,完整向量是100维
# 3. 计算两个词的语义相似度(如"car"和"accident")
similarity = model.wv.similarity('car', 'accident')
print(f"\n'car'与'accident'的相似度:{similarity:.4f}")
# 4. 额外验证:"sadly"和"fire"的相似度(灾难相关关联)
similarity_sadly_fire = model.wv.similarity('sadly', 'fire')
print(f"'sadly'与'fire'的相似度:{similarity_sadly_fire:.4f}")
# ===================== 第六步:生成文档向量(用于后续模型训练) =====================
# 方法:将文本中所有词的向量取平均,得到文档级向量
def get_doc_vector(text_seg, model):
"""
将分词后的文本转换为文档向量
:param text_seg: 分词后的文本列表
:param model: 训练好的Word2Vec模型
:return: 文档向量(100维)
"""
import numpy as np
vec_list = [model.wv[word] for word in text_seg if word in model.wv.key_to_index]
if len(vec_list) == 0:
return np.zeros(100) # 无有效词时返回全0向量
return np.mean(vec_list, axis=0)
# 生成所有文本的文档向量
import numpy as np
doc_vectors = np.array([get_doc_vector(seg, model) for seg in corpus])
print(f"\n文档向量形状:{doc_vectors.shape}") # (4, 100):4个文档,每个100维
print(f"第4条文本(car sadly car caught up fire)的文档向量(前10维):")
print(doc_vectors[3][:10])
GloVe
GloVe 词嵌入方法由 Pennington 等人在斯坦福大学开发,用于自然语言处理。它被称为全局向量,因为该模型直接捕获了全局语料库的统计信息。GloVe 在单词类比和命名实体识别问题上表现出色。
该技术由于采用了更简单的最小二乘代价函数或误差函数,降低了模型训练的计算成本,从而生成了不同且更优的词嵌入。它利用了局部上下文窗口方法(例如 Mikolov 的 skip-gram 模型)和全局矩阵分解方法来生成低维词表示。
潜在语义分析(LSA)是一种基于全局矩阵分解的方法,虽在单词类比任务中表现一般,但它利用统计信息来构建向量结构的思路具有参考性;而 Skip-gram 方法在类比任务中表现更好,却因未利用全局统计数据,无法充分捕捉词的关联信息。
与 Word2Vec(基于局部上下文构建词嵌入)不同,GloVe 聚焦全局上下文生成词嵌入,这是它与 Word2Vec 的核心差异 —— 在 GloVe 中,词与词的语义关系是通过共现矩阵来体现的。
以这两个句子为例:
- I am a data science enthusiast
- I am looking for a data science job
GloVe 会基于 “窗口大小 = 1”(单词连续出现的次数),构建如下共现矩阵:
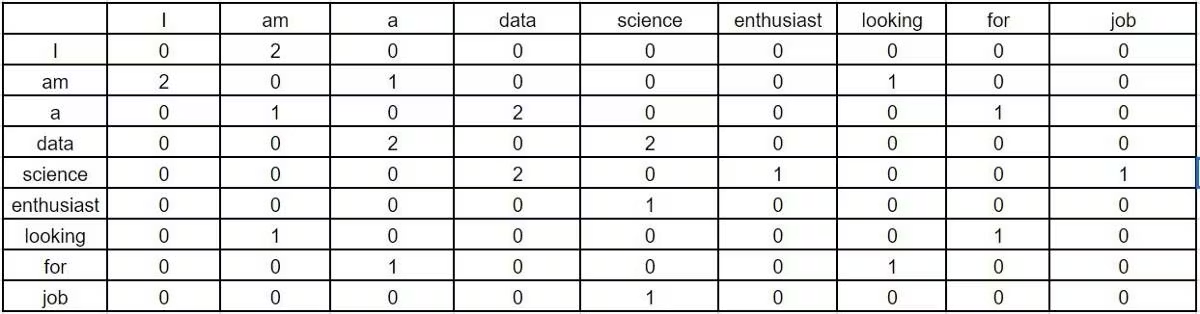 矩阵中的值代表 “对应行的词出现在对应列的词的上下文中的次数”。若语料包含 100 万个不同单词,共现矩阵的规模会达到 100 万 ×100 万。
矩阵中的值代表 “对应行的词出现在对应列的词的上下文中的次数”。若语料包含 100 万个不同单词,共现矩阵的规模会达到 100 万 ×100 万。
GloVe 的核心思路是:单词的共现信息,是学习词表示的关键依据。
我们再看斯坦福大学 GloVe 论文中的经典示例:以目标词 “ice” 和 “steam” 为例,统计它们与词汇表中其他词的共现概率,以下是来自一个包含 60 亿词的语料库的一些实际概率:

这里的核心公式是:
- 代表“词 出现在词 的上下文中的概率”。
- :共现矩阵中词 与词 的共现次数,即:
- :词 的上下文中出现的所有词的总次数,数学表达式为: 假设 k = solid,即与 ice 相关但与 steam 无关的词。预期 Pik / Pjk 比值会很大。类似地,对于与 steam 相关但与 ice 无关的词 k,例如 k = gas,该比值会很小。对于像 water 或 fashion 这样的词,它们要么分别与 ice 和 steam 都相关,要么都与两者都无关,该比值应该接近于 1。
概率比值比原始概率更能区分相关词(例如 solid 和 gas)和不相关词(例如 fashion 和 water)。它也能更好地区分两个相关词。因此,在 GloVe 中,词向量学习的出发点是共现概率的比值,而不是概率本身。
理论就讲到这里,现在开始写代码!
# ===================== 1. 导入所需库 =====================
# nltk:自然语言处理基础库,用于文本预处理
import nltk
# re:正则表达式库,用于文本清洗(移除非字母字符)
import re
# stopwords:nltk内置的停用词库(如the/a/an等无意义词汇)
from nltk.corpus import stopwords
# Glove相关库:Corpus用于构建语料库,Glove用于训练词嵌入
from glove import Corpus, Glove
# ===================== 2. 文本预处理(GloVe输入要求:分词后的文档列表) =====================
# 初始化空列表,用于存储预处理后的分词语料
corpus = []
# 遍历所有文本数据(X为原始文本列表,如推文/句子集合)
for i in range(0, len(X)):
# 步骤1:移除文本中所有非字母字符(仅保留字母和空格),例如将"storm!!123"转为"storm "
tweet = re.sub("[^a-zA-Z]", " ", X[i])
# 步骤2:将所有字符转为小写,统一格式(如"Storm"→"storm")
tweet = tweet.lower()
# 步骤3:按空格分词,将字符串转为单词列表(如"heavy storm"→["heavy", "storm"])
tweet = tweet.split()
# 步骤4:将预处理后的分词列表加入语料库(若需过滤停用词,可取消下方注释)
# tweet = [word for word in tweet if not word in set(stopwords.words('english'))]
corpus.append(tweet)
# ===================== 3. 训练GloVe词嵌入 =====================
# 初始化Corpus对象,用于构建GloVe所需的共现矩阵
corpus_model = Corpus()
# 构建语料库的共现矩阵(核心步骤)
# window=5:上下文窗口大小,即每个词的前后各5个词视为上下文
corpus_model.fit(corpus, window=5) # 修正原代码:text_corpus→corpus(变量名统一)
# 初始化GloVe模型
# no_components=100:词嵌入向量的维度(常用100/200/300)
# learning_rate=0.05:学习率,控制模型参数更新步长
glove = Glove(no_components=100, learning_rate=0.05)
# 训练GloVe模型(基于共现矩阵)
# corpus.matrix:构建好的共现矩阵
# epochs=100:训练轮数,迭代次数越多拟合效果越好(但易过拟合)
# no_threads=4:训练使用的线程数(根据CPU核心数调整)
# verbose=True:打印训练过程(如每轮损失值)
glove.fit(corpus_model.matrix, epochs=100, no_threads=4, verbose=True)
# 将语料库的词汇字典添加到GloVe模型中(关联单词与索引,方便后续查询)
glove.add_dictionary(corpus_model.dictionary)
# ===================== 4. 验证词嵌入效果:查找相似词 =====================
# 查找与"storm"语义最相似的10个词(返回词+相似度)
# number=10:指定返回相似词的数量
similar_words = glove.most_similar("storm", number=10)
# 打印结果,直观查看相似词
print("与'storm'最相似的10个词:")
for word, similarity in similar_words:
print(f" {word}: {similarity:.4f}")
单词元组及其预测概率列表:

BERT
BERT 是一种基于 Transformer 模型的自然语言处理(NLP)算法,包含两个核心变体:参数规模为 1.1 亿的 BERT-Base,以及参数达 3.4 亿的 BERT-Large。
它的核心优势是依赖注意力机制,生成与上下文强关联的高质量词嵌入:在训练过程中,输入会逐层经过 BERT 的网络结构,而每一层的注意力机制都能同时捕捉 “当前词左右两侧的语义关联”,这让它的词表示更贴合文本的实际语境。
相比词袋、Word2Vec 等传统方法,BERT 是更先进的技术 —— 它基于维基百科、海量语料预训练得到通用模型,再通过 “微调” 就能适配特定任务的数据集,因此生成的词嵌入效果更优。目前它在语言翻译等 NLP 任务中应用广泛。
它在语言翻译任务中有着广泛的应用。
总结
词嵌入技术是训练 GRU、LSTM、Transformer 等深度学习模型的基础,这些模型在情感分类、命名实体识别、语音识别等 NLP 任务中都取得了显著效果。
各类文本表示技术的典型应用场景总结如下:
- 词袋模型:文本特征初步提取
- TF-IDF:信息检索、关键词提取
- Word2Vec:语义分析类任务
- GloVe:词语类比、命名实体识别
- BERT:语言翻译、问答系统
索引算法
GRAPH
图索引 Graph 这里通常指基于图结构的索引算法的总称。图索引普遍在高维空间中表现好,召回率高,但内存开销和构建时间是共同挑战。
- 原理:将所有向量视为图的节点,根据向量间的相似度(距离)建立边,形成邻近图(Proximity Graph)。搜索时从入口节点开始贪心遍历,逐步找到最近邻。
- 分类:NSW、KNN-Graph、HNSW 等。
- NSW(Navigable Small World)见如其名,不分层的导航。
- HNSW 是 分层 NSW(Hierarchical Navigable Small World),带多层结构。是其中最流行的一种实现。
- 普通单层 KNN-Graph/NSW 只有全局
max_degree,没有分层参数。
HNSW
HNSW 全称 Hierarchical Navigable Small World Graph(分层可导航小世界图),是一种 基于图的近似最近邻(ANN) 算法。
- 核心思想:把向量构建成一个“可导航”的小世界图(邻居连接),查询时从图上的某个入口点出发,沿着“更近的邻居”一步步贪心走,快速逼近目标最近邻。
- 上层:节点少、连接稀疏,像“高速公路”,用于快速粗定位(导航)。
- 下层:节点多、连接稠密,用于精细匹配。
- 每个节点(向量)会连接到若干“邻居”(根据距离,如欧氏距离或余弦相似度),形成“小世界网络”特性——任意两点之间路径很短。
- 检索方式:
- 建图:每个向量会连接到若干个“近邻”(参数常见叫
M或 neighbors)。 - 分层:有多层图(上层更稀疏、下层更稠密)。查询先在高层“快速粗定位”,再逐层下沉到低层“精细搜索”。
- 建图:每个向量会连接到若干个“近邻”(参数常见叫
- 核心优势:
- 在很多数据分布上,召回率(通常 95%+)/ 速度(对数级复杂度)的折中非常好,是业界常用的通用 ANN 方案。
- 在内存中表现优秀,适合实时查询。
- 缺点:
- 建图成本高:插入每个点都要找邻居并更新图结构,整体写入/构建比较慢。
- 内存占用大:图边需要额外存储(每个点存邻居列表)。
- 操作复杂:增量插入/删除相对复杂,大规模数据或带强过滤(Filter)时性能可能不稳定。
- 数据分布极端时容易出问题:比如大量重复/近重复向量在同一时间段写入,可能出现你文档里的 “孤岛(非连通子图)”。
- 典型使用:Milvus、Weaviate、PGVector、Faiss 等向量数据库中默认或高性能选项。常用于 RAG、推荐系统、图像检索等对速度和精度要求高的场景。
- 参数:
- 索引构建参数
M/max_connections/neighbors- 全称:每层最大邻居数(Max Connections per Layer)
- 作用:控制 HNSW 每层图中,每个节点最多有多少条出边(连接多少个邻居)
- 典型值:16 / 32 / 64
efConstruction- 全称:Exploration Factor at Construction Time,构建时候选集大小。
- 作用:插入向量时,为寻找最优邻居,在每层搜索的候选列表长度
- 典型值:100–300(通常为
M的 2–5 倍)
- 查询参数
efSearch(或ef):搜索时保留的候选邻居数量
- 线程数 / 队列 / 并行度:HNSW 索引构建 / 查询的工程参数,控制并发
- 索引构建参数
IVF_GRAPH
IVF_GRAPH 全称 Inverted File Graph(倒排文件图索引),也常写作 IVF-HNSW。
- 原理:IVF(聚类分桶) + Graph(HNSW) 的组合。
- IVF:先把向量空间切成很多“桶/簇”(常见做法是 KMeans 得到若干个中心点),每个簇有一个质心(Centroid),形成倒排文件(Inverted File)。
- GRAPH(HNSW 图):每个簇内部 不再用 Flat 列表,而是构建 HNSW 图(或优化 Graph)。
- 检索方式:
- 计算 query 向量与各个聚类中心的距离,选最近的
nprobe个桶。 - 只在这些簇内部的 HNSW 图上进行图遍历搜索。
- 计算 query 向量与各个聚类中心的距离,选最近的
- 优点:
- 结合了 IVF 的“先粗筛缩小范围”和 HNSW 的“图内快速精确搜索”。
- 检索效率极高,因为先分桶,大幅减少要访问的向量数量。特别适合超大规模数据(亿级甚至十亿级)。
- 通常能做到 写入更快、查询更快(尤其在大规模时),同时内存压力也更可控(取决于实现是否把某些结构 offload)。
- 缺点:
- 召回率会受 IVF 的“分桶质量”和
nprobe影响:如果 query 的真实近邻落在没被探测到的桶里,会产生漏召回。(不过通过更好的中心点、增大nprobe、或更合理训练可以改善) - 需要训练/采样:例如你文档提到“1 亿向量随机采样 10w 条作为中心点向量 1000:1”,这就是 IVF 的典型做法。
- 召回率会受 IVF 的“分桶质量”和
- 适用场景:数据量极大(上亿以上)、对检索性能要求高、需要平衡速度/内存/精度的生产环境。常搭配 PQ(Product Quantization)量化进一步压缩内存,形成 IVF_GRAPH_PQ。
- 参数:
- 索引构建参数
nlist:桶数/cluster 数)、训练样本量/采样比例、中心点生成方式(kmeans/随机)
- 查询参数
nprobe:检索时的探测桶数
- 索引构建参数
孤岛问题 & 漏召回
孤岛问题: 在 HNSW 图索引中,当短时间内插入大量重复标题、重复内容或高度相似的向量 时,图结构容易出现“孤岛”(isolated clusters / disconnected components)。
具体形成过程
- 新插入的向量彼此之间距离极小(几乎相同或高度相似)。
- HNSW 在插入每个新节点时,会执行“找邻居”(neighbor selection):从当前图中搜索候选,然后建立双向边。
- 因为这些新向量互相距离最小,新节点优先互相连接,形成一个局部密集小团簇(dense local cluster)。
- 这个小团簇与原有大图之间的“桥接边”(long-range edges / bridging edges)很少或几乎没有。
- 结果:整个图被分裂成多个连通分量(connected components)。有些向量所在的“孤岛”与主图的连通性很差。
查询时的后果
- HNSW 查询从入口点(entry point,通常是上层图的一个 hub 节点)开始,进行贪心遍历(greedy routing):每次都向当前最相似的邻居移动,逐步“下沉”到下层。
- 如果目标最近邻位于某个孤岛里,而遍历路径走不到或者走不出那个孤岛(因为缺少桥接边),算法就会陷入局部最优(local minimum),提前停止。
- 最终结果:漏召回(missing recall)—— 本该被召回的相似向量没有出现在 Top-K 结果中,召回率(recall@K)明显下降。
为什么重复/相似向量特别容易引发这个问题?
- 重复向量会形成“高密度陷阱”(dense region trap)。算法在搜索候选邻居时,大量计算都消耗在这些密集区域,难以“跳出来”建立跨区域的长距离连接。
- 增量插入(而非一次性全量构建)会加剧问题:后插入的向量只能基于已有的局部视图找邻居。
- 带过滤(filter)场景更严重:过滤后剩余向量更容易被分割成多个孤岛,图遍历几乎失效。
实际影响:
- 在 RAG、推荐、语义搜索中,漏召回会导致 LLM 缺少关键上下文,回答质量下降。
- 这个问题在 Faiss、Milvus、Weaviate 等实现中都被观察到,尤其当数据有天然聚类或突发批量相似内容时。
解决方案
1. 写入打散 Write Scattering / Insertion Shuffling
核心思路: 在数据写入 / 索引构建阶段,故意打乱向量的插入顺序(shuffle),避免相似向量“扎堆”连续插入,从而提升图的全局连通性(global connectivity)和 small-world 特性。
为什么有效?
- 随机/打散插入让新向量有机会接触到不同区域的已有节点,更容易建立“长距离桥接边”。
- 避免了“相似向量互相抱团”形成孤岛的情况,让图结构更均匀、更具导航性。
- 即使数据本身高度聚类,打散也能显著降低孤岛概率,提高基线召回率。
常见实现方式:
- 离线全量构建:把所有向量先随机打乱(shuffle),再批量插入构建 HNSW。这是效果最好的方式。
- 实时增量写入:
- 使用随机缓冲区:积累一批向量后随机打乱再插入。
- 随机分片 / 轮询插入不同分区。
- 周期性重构索引(re-index)时进行 shuffle。
- 部分向量数据库支持插入时添加少量噪声扰动,或在层级选择时引入随机性。
实际效果与局限:
- 能显著提升召回率(某些 benchmark 显示插入顺序可导致 recall 相对变化达 17%)。
- 对查询速度几乎无负面影响。
- 局限:无法 100% 消除孤岛(尤其数据天然极度相似时),需要与其他手段配合。一次性全量 shuffle 比纯增量插入效果更好。
工程建议:在构建索引前一定要 shuffle 数据;生产环境中可结合数据分区策略实现“写入打散”。
2. 增大 M / efConstruction
这两个是 HNSW 索引构建时的核心超参数,直接决定图的连通密度和质量,从而对抗孤岛问题。
- M(Maximum number of connections per node,每节点最大邻居数):
- 含义:每个节点在每层最多允许建立的双向边数量(出度/入度)。
- 作用:控制图的稠密度和连通性。
- M 越大 → 每个节点连接的邻居越多 → “高速公路”越多 → 跨孤岛的路径更容易建立 → 抗孤岛能力越强,召回率越高。
- 典型范围:默认 8
32,高召回场景可设 48128(内存允许时)。
- 代价:内存占用显著增加(每条边都要存储),构建时间略长,查询时遍历的边也稍多。
- 调优建议:内存充足、对召回敏感 → 增大 M;它是影响召回最直接的参数之一。
- efConstruction(ef during construction,构建时的候选探索范围):
- 含义:插入每个新节点时,维护的动态候选列表大小(beam width / 探索深度)。
- 作用:越大 → 构建时对每个节点探索的候选邻居越多 → 能找到质量更高、更全局的邻居(而非只看局部最近的)→ 图质量更好,孤岛更少,召回率提升。
- 典型范围:默认 100
200,高精度场景设 300512+(甚至更高)。 - 代价:主要增加构建时间(插入变慢),对最终索引大小和查询速度影响相对较小。
- 调优建议:构建时间窗口允许时尽量调大;通常与 M 配合(M 大时 efConstruction 也要相应增大)。规则经验:efConstruction ≥ 2 × M。
总结:增大 M + efConstruction 提升构建阶段的图质量,从而提升 HNSW 召回率。
查询阶段补充:还有 efSearch(或 ef)参数,作用类似 efConstruction,但只影响单次查询的探索范围(越大召回越高,但查询越慢)。
3. IVF 的 nlist / nprobe 兜底
当纯 HNSW 仍有漏召回风险时(尤其孤岛、强过滤、超大规模场景),常用 IVF(Inverted File,倒排文件) 作为兜底策略,或直接使用 IVF_GRAPH / IVF-HNSW 混合索引。
- nlist(构建参数,聚类簇数量):
- 把整个向量空间用 k-means 等算法划分成 nlist 个簇(Voronoi cells),每个簇有一个质心。
- nlist 越大 → 聚类越细,每个簇内向量更相似,但构建时间和内存略增。
- 典型值:几百到几万(根据数据规模)。
- nprobe(查询参数,探查簇数量):
- 查询时,先计算查询向量与所有质心的距离,选出最近的 nprobe 个簇。
- 然后只在这 nprobe 个簇内进行后续搜索(可以是 Flat、PQ 量化,或 HNSW 图搜索)。
- 兜底作用:增大 nprobe → 检查的范围越广 → 即使某个簇内有孤岛漏召回,也可能在其他簇找到目标向量 → 大幅降低整体漏召回概率。
- 典型值:默认 10~64,高召回需求时动态调到 100+。
- 代价:nprobe 越大,查询延迟线性增加(要扫描更多向量/簇)。
兜底用法示例:
- 切换到 IVF-HNSW(IVF_GRAPH):先用 IVF 粗筛簇(快速缩小范围),再在选中的簇内用 HNSW 精搜。结合了 IVF 的可扩展性和 HNSW 的高精度。
- 混合检索:HNSW 作为主召回通道 + IVF(大 nprobe)作为备用候选池,最后合并重排(rerank)。
- 优势:在带强过滤、数据量极大、或召回要求极高时,IVF 的聚类结构更稳健,能有效“兜住”HNSW 的孤岛问题。
整体工程实践建议
- 预防为主:写入时打散 + 调大 M 和 efConstruction → 提升 HNSW 自身质量。
- 查询增强:调大 efSearch。
- 兜底保障:结合 IVF(合理 nlist + 动态/较大 nprobe),或使用混合索引。
- 进阶:周期性重构索引、后处理重排、量化压缩(PQ)、监控 recall@K(用 Ground Truth 数据集离线评测)。
- 权衡:召回率越高,通常构建时间、内存、查询延迟也越高。建议在具体向量数据库(Milvus、Faiss、PGVector 等)中用实际数据做 benchmark 调优。
总结
索引算法主要有以下几类:
- FLAT:暴力计算,目标向量依次和所有向量进行距离计算,此方法计算量大,召回率 100%。适用于对召回准确率要求极高的场景
- GRAPH:图索引,内嵌深度优化的 HNFW 算法,主要应用在对性能和精度均有较高要求且单 shard 中文档数量在千万个以内的场景
- IVF_GRAPH:算法将 IVF 与 HNSW 结合,对全量空间进行划分,每一个聚类中心向量代表一个子空间,极大地提升检索效率,同时会带来微小的检索精度损失。适用于数据量在上亿以上同时对检索性能要求极高的场景。
什么时候选哪个?
- 数据量中等(百万~千万级),追求高召回 + 低延迟:优先
GRAPH/HNSW - 数据量巨大(上亿级),更重视整体吞吐、成本、构建时间:倾向
IVF_GRAPH - 重复/近重复向量特别多,且批量集中写入:纯图索引更容易出现构图质量问题(孤岛/连通性差),
IVF_GRAPH往往更稳(但仍需调参与训练质量)
Bi-Encoder vs Cross-Encoder
Bi-Encoder 已经计算了 Query-Doc 的向量相似度,Cross-Encoder 为什么仅凭捕抓 Query-Doc 语义关系就比 Bi-Encoder 靠谱?
既然 Bi-Encoder(双塔模型)已经把 Query 和 Doc 都编码成了高维向量,并且计算了余弦相似度,这不就是在做“语义匹配”吗?为什么效果被 Cross-Encoder(交叉编码器)全方位碾压?
答案的核心,隐藏在深度学习中最残酷的物理限制里:“信息瓶颈(Information Bottleneck)”与“交互时机(Interaction Stage)”。
在学术界和工业界,这被称为 Late Interaction(延迟交互) 与 Early Interaction(早期交互) 的架构代差。
我们把这两者的底层计算图切开来看,你就完全明白了:
1. Bi-Encoder 的致命伤:盲人摸象与信息塌缩 (Late Interaction)
Bi-Encoder 的计算公式可以抽象为:
它的工作机制是:Query 塔单独编码 Query,Doc 塔单独编码 Doc。两者在编码过程中互不相见,完全物理隔离。
这会带来两个毁灭性的问题:
-
信息压缩塌缩(The Compression Bottleneck):
假设你的 Doc 是一篇 2000 字的深度技术长文。在 Bi-Encoder 中,这 2000 个字无论包含多少错综复杂的知识点,最终都必须被“无损且无偏”地强行压缩进一个固定维度(比如 768 维)的单一向量 中。
这就好比让一个学生去死记硬背一本 500 页的教科书,而且不告诉他考试题目是什么。为了兼顾所有内容,他只能记住极其模糊的“全局概要”,大量细粒度的局部信息在 Pooling(池化)操作的那一瞬间就永久丢失了。
-
静态表征缺乏上下文(Static Representation):
因为编码时不知道 Query 是什么,Doc 中词汇的 Embedding 是静态的。对于“苹果”这个词,Bi-Encoder 只能给出一个介于“水果”和“手机”之间的折中向量。当真正的 Query(“乔布斯”)砸过来时,Doc 塔已经来不及调整了,只能用那个折中的向量去硬算点积。
2. Cross-Encoder 的降维打击:全连接注意力矩阵 (Early Interaction)
Cross-Encoder 的计算公式是:
它的工作机制是:直接把 Query 和 Doc 拼接成一个长序列(例如 [CLS] Query [SEP] Document [SEP]),然后一股脑扔进 Transformer 的 12 层(或更多)网络中。
为什么它准得可怕?因为它在第一层就开始了“极其暴力的特征交叉”:
-
Token 级别的 Cross-Attention(交叉注意力):
在 Cross-Encoder 的每一层 Self-Attention 机制中,Query 中的每一个 Token,都在和 Document 中的每一个 Token 进行 的点积计算矩阵。
这意味着,它不是在比较两个“被高度压缩的总结”,而是在做极其精细的词对词、句对句的对齐扫描。
-
动态上下文感知(Dynamic Contextualization):
有了 Cross-Encoder,当 Query 是“乔布斯”时,注意力机制(Attention Matrix)会瞬间将权重倾斜,激活 Doc 中所有关于“苹果公司”、“iPhone”的隐藏神经元。Doc 中“苹果”这个词的表征,会因为 Query 的存在,被实时动态重塑为纯粹的“科技公司”语义,从而给出极其确信的高分。
3. 一个极端的对比案例:关系与词序的捕获
假设 Query 是:"如何防止 Elasticsearch 节点 OOM"
候选 Doc 1:"Elasticsearch 节点 OOM 的排查与防止策略"(高度相关)
候选 Doc 2:"防止 JVM OOM 的策略,以及 Elasticsearch 节点挂掉的排查"(拼凑匹配,语义有偏差)
-
Bi-Encoder 的视角: 两个 Doc 都会被分别压缩。由于 Doc 2 也包含了“防止”、“Elasticsearch”、“节点”、“OOM”这些高频特征向量,它的全局平均向量极其容易和 Query 的向量在 768 维空间中发生“虚假对齐(False Alignment)”,算出极高的余弦相似度。
-
Cross-Encoder 的视角: Transformer 内部的注意力矩阵会进行严格的句法依存树扫描。它能敏锐地发现 Doc 2 中“防止”修饰的是“JVM OOM”,而“Elasticsearch 节点”修饰的是“挂掉”。Query 要求的“防止 -> 节点 OOM”的注意力连线在 Doc 2 中断裂了。因此,它会无情地给 Doc 2 击穿底价的低分。
总结
Bi-Encoder 就像是两个互不相识的人各自写了一份自我介绍(向量),然后 HR(余弦相似度)只看这两张纸来判断他们是否合拍。由于信息被严重压缩,这种判断注定是粗粒度、高容错的,所以它只能用于召回阶段(Retrieval) 去海选。
Cross-Encoder 则是把这两个人关进同一个密室(拼接输入),让他们针对每一个细节进行长达 12 轮的深度辩论(12 层 Transformer 交叉注意力)。这种 Token 级别的暴力纠缠,赋予了它极其恐怖的语义辨别力,因此它坐稳了精排(Rerank) 环节的王座。