评估指标
🎯 命中类指标
不考虑位置,只关心“是否命中相关文档”
1️⃣ 准确率 Precision
- 类别:单 Query 指标
- 意义:衡量 Top-K 中真正相关的比例(检索结果的纯度)。
- 计算方式:Top K 结果里,有多少相关文档。
- 公式:
- 全局指标:平均准确率
- 计算方式:所有 Query 的准确率平均值。
2️⃣ 召回率 Recall
- 类别:单 Query 指标
- 意义:衡量所有真实相关文档中,有多少被检索到(检索结果的完整度)。
- 公式:
- 全局指标:平均召回率
- 计算方式:所有 Query 的召回率平均值。
3️⃣ F1 分数 F1-Score
- 类别:单 Query 指标
- 意义:F1 分数是精确率和召回率的调和平均数,它同时兼顾了这两个指标,在它们之间寻求平衡。当精确率和召回率都高时,F1 分数也高。
- 公式:
4️⃣ 命中率 Hit Rate
- 类别:全局指标。
- 意义:是否能检索到相关内容。
- 计算方式:Top K 结果里,有没有至少 1 个相关文档。
- 公式:
🔁 排序质量指标
排序类指标又可以分为两类:
- 二元排序指标:位置 + 相关性只有 0(不相关)或 1(相关)两种状态
- 多元排序指标:位置 + 相关性是连续或多级离散打分的
1️⃣ 倒数排名 Reciprocal Rank
- 类别:单 Query 指标、二元排序
- 意义:关注第一个相关文档出现在什么位置。
- 计算方式:第一个相关文档的排序位置,如果该 Query 没有召回任何相关文档则 RR 为 0。
- 公式:
- 全局指标:平均倒数排名
- 计算方式:所有 Query 的倒数排名平均值
2️⃣ 期望倒数排名 Expected Reciprocal Rank
- 意义:模拟用户从上到下浏览的“停止概率”,比 MRR 更贴近真实行为
- 公式:
3️⃣ 平均精确率 Average Precision
- 类别:单 Query 指标、二元排序
- 意义:评估单个 Query 排序质量的核心指标。综合考虑 Precision 在不同召回位置的变化,比 Precision@K 更全面。
- 计算方式:只在相关文档出现的位置计算 Precision,然后取平均。Average Precision:
- 全局指标:平均倒数排名
- 计算方式:所有 Query 的 AP 平均值
4️⃣ 归一化折损累计增益 NDCG
- 类别:单 Query 指标、多元排序
- 意义:消除不同 Query 的相关文档数量差异,可以对比。最能反映“用户真正看到的好结果”质量。
- 计算方式:把 DCG 除以 IDCG。
- 公式:
- 公式推演:
- CG@K (Cumulative Gain,累计增益)
- CG 表示对 K 个 item 的 Gain 进行累加,其中 Gain 表示列表中每一个 item 的相关性分数 ,不考虑在搜索结果的位置信息。假设排第 位的文档的真实相关性得分为 :
- eg: ==11
- DCG@K (Discounted Cumulative Gain,折损累计增益)
- 如果有效 Item 在列表中排的较低的话,应该对列表的评分惩罚,惩罚和有效结果的排位有关。所以就加了衰减因子:
- eg: =3+1.9+1+0.86+0.39=7.14,=3+1.3+0.5+1.3+0.7=6.8
- IDCG@K (Ideal Discounted Cumulative Gain, 理想折损累计增益)
- 为了把不同查询、不同相关性分布的 DCG 做归一化对比,我们需要一个 “理论上的天花板” 作为基准。这个基准就是:把所有结果按相关性从高到低排好序,再按 DCG 公式计算得到的理想值:
- eg: ==7.15
- NDCG@K (Normalized Discounted Cumulative Gain,归一化折损累计增益)
- DCG 存在的问题:不同 Query 的相关性分布、文档数量不同,DCG 的绝对数值无法横向对比。比如 Query A 有 10 个高相关文档,DCG 很高;Query B 只有 2 个,DCG 再高也比不过 A,没法直接说哪个排序更好。因此必须引入 IDCG(Ideal DCG,理想状态下的完美排序得分)作为分母进行归一化。
- NDCG 的核心目的:用「当前排序的 DCG」除以「理论上能达到的最高 DCG(即 IDCG)」,把结果归一化到 0~1 之间,消除不同 Query 之间的差异,让结果可以公平对比。
- 首先,将当前 Query 下所有存在的真实相关文档按 Label 值从大到小执行理论上的完美排序(Perfect Ranking),计算其截断到 K 的 DCG,记为 :
- 最后,计算归一化得分,该值永远被严格收敛在 之间:
- CG@K (Cumulative Gain,累计增益)
🧩 RAG 特有指标
Token Hit Rate(Token 命中率/有效 Token 占比)Content Recall(上下文召回):检索是否覆盖答案所需信息,Context Recall = 检索到的有用信息 / 所需信息。Content Precision(上下文精确率):RAGAS 框架核心指标。检索结果中有多少是“真正有用的”,Context Precision = 有用内容 / 检索内容。Faithfulness(忠诚度):生成是否“基于检索内容”。Answer Relevance(答案相关性): 最终答案是否回答问题。UDCG:在 DCG 的基础上,给无关 Chunk 加「干扰惩罚项」,同时用大模型的位置敏感度来调整权重。
评估目标
不管 RAG 系统怎么变,其核心离不开两个关键部分:检索和生成。
- 检索质量:检索系统已经发展多年,在搜索引擎、推荐系统等领域都广泛使用,也相应有很多衡量检索质量的指标,比如命中率、MRR 和 NDCG。
- 生成质量:生成质量主要用于评估模型基于检索到的内容生成连贯、准确答案的能力。其评估通常也包含如下两方面(也都可以采用人工评估和自动评估的方式):
- 有标注评估:重点评估产生信息的准确性
- 无标注评估:重点评估生成答案的真实性、相关性和无害性等
评估维度
RAG 的评估通常强调 3 个主要的质量分数和 4 个基本的能力,它们为 RAG 模型的两个主要目标提供了相应信息。
质量分数
- Context Relevance(上下文相关性):评估检索到的上下文的精确性和特异性,确保相关性并最大限度降低与无关内容相关的处理成本
- Answer Faithfulness(答案真实性):确保生成的答案与检索到的上下文保持一致并避免矛盾
基本能力
- Noise Robustness(噪声鲁棒性):评估模型处理与问题相关但缺乏实质性信息的噪声文档的能力
- Negative Rejection(否定拒绝):评估模型对于检索到的文档不包含回答问题的必要知识时不做出响应的辨别力
- Information Integration(信息融合):评估模型综合来自多个文档的信息以解决复杂问题的能力
- Counterfactual Robustness(反事实鲁棒性):评估模型识别和忽略文档中已知不准确信息的能力
本节将探讨 RAG 评估的理念与方法,并围绕 “RAG 三元组(RAG Triad)” 展开。
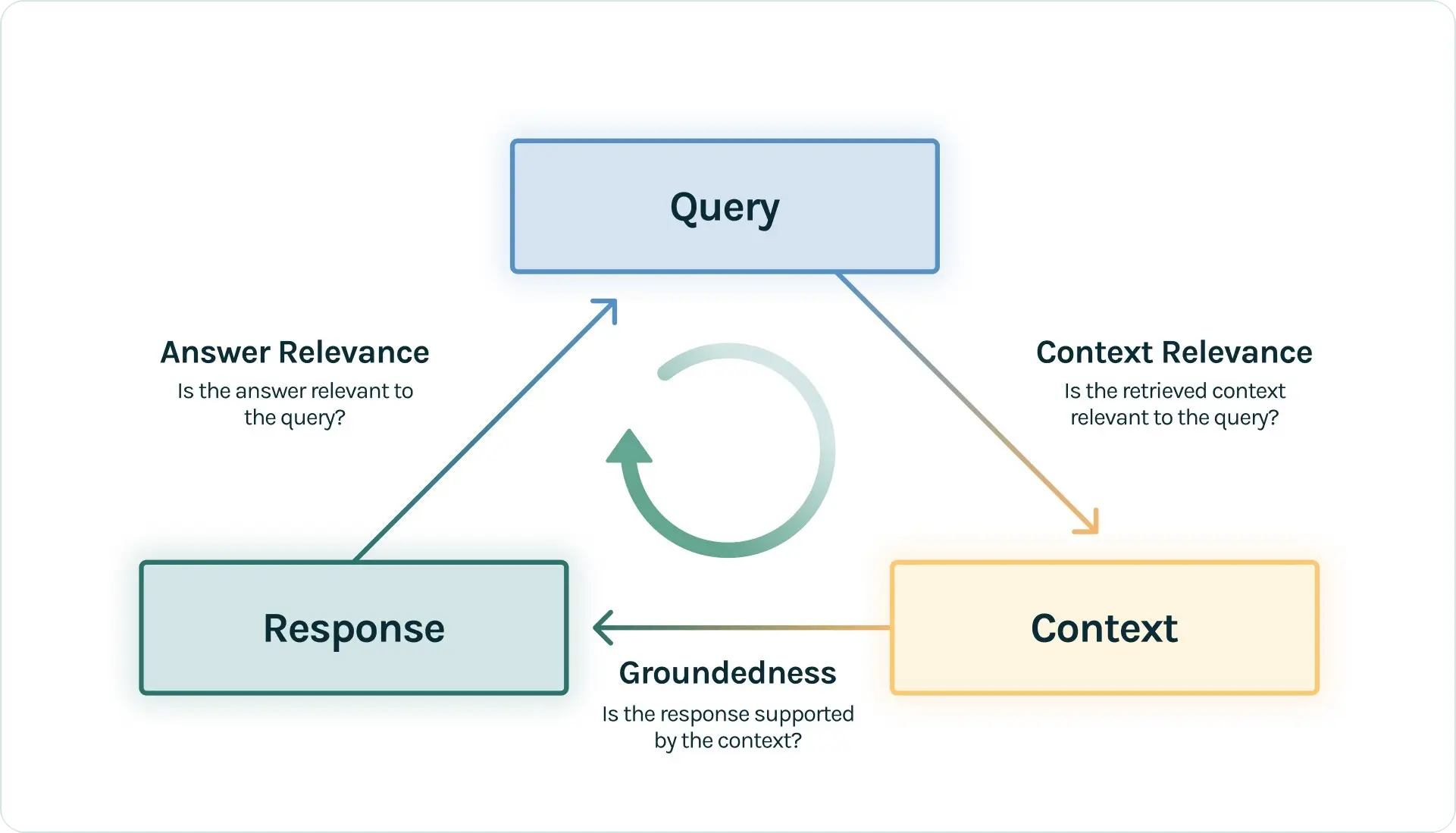
该架构包含以下三个维度,并在 TruLens 等工具中有深入的应用:
(1)上下文相关性 (Context Relevance)
- 评估目标: 检索器(Retriever)的性能。
- 核心问题: 检索到的上下文内容,是否与用户的查询(Query)高度相关?
- 重要性: 检索是 RAG 应用在响应用户查询时的第一步。如果检索回来的上下文充满了噪声或无关信息,那么无论后续的生成模型多么强大,都没法做出正确答案。
(2)忠实度 / 可信度 (Faithfulness / Groundedness)
- 评估目标: 生成器的可靠性。
- 核心问题: 生成的答案是否完全基于所提供的上下文信息?
- 重要性: 这个维度主要在于量化 LLM 的“幻觉”程度。一个高忠实度的回答意味着模型严格遵守了上下文,没有捏造或歪曲事实。如果忠实度得分低,说明 LLM 在回答时“自由发挥”过度,引入了外部知识或不实信息。
(3)答案相关性 (Answer Relevance)
- 评估目标: 系统的端到端(End-to-End)表现。
- 核心问题: 最终生成的答案是否直接、完整且有效地回答了用户的原始问题?
- 重要性: 这是用户最直观的感受。一个答案可能完全基于上下文(高忠实度),但如果它答非所问,或者只回答了问题的一部分,那么这个答案的相关性就很低。例如,当用户问“法国在哪里,首都是哪里?”,如果答案只是“法国在西欧”,那么虽然忠实度高,但答案相关性很低。
你可能觉得忠实度和答案相关性很相似,但它们的侧重点是不同的。忠实度更关注模型是否严格遵循了上下文,而答案相关性则更关注模型是否直接、完整且有效地回答了问题。
通过对这三个维度进行评估,可以对 RAG 系统的表现有一个全面而细致的了解,并能准确定位问题所在:是检索出了问题,还是生成环节有待改进。
评估工作流
虽然上面把评估分成了三个部分,但实际上可以把评估过程拆解为两个主要环节:检索评估和响应评估。
检索评估
检索评估聚焦于 RAG 三元组中的 上下文相关性 (Context Relevance),本质上是一次白盒测试。此阶段的评估需要一个标注数据集,其中包含一系列查询以及每个查询对应的真实相关文档。
- 上下文精确率 (Context Precision)
- 上下文召回率 (Context Recall):
- F1 分数 (F1-Score):
- 平均倒数排名 (MRR - Mean Reciprocal Rank):
- 平均准确率均值 (MAP - Mean Average Precision):
要计算上述所有指标,前提是拥有一个高质量的标注数据集,其中包含了查询和每个查询对应的“真实”相关文档。
响应评估
响应评估覆盖了 RAG 三元组中的 忠实度 和 答案相关性。此环节通常采用 端到端 的评估范式,因为它直接衡量用户感知的最终输出质量。无论采用何种评估方法,都主要围绕以下两个核心维度展开:
(1)忠实度 / 可信度:衡量生成的答案在多大程度上可以由给定的上下文所证实。一个完全忠实的答案,其所有内容都必须能在上下文中找到依据,以此避免模型产生“幻觉”。
(2)答案相关性:衡量生成的答案与用户原始查询的对齐程度。一个高相关性的答案必须是直接的、切题的,并且不包含与问题无关的冗余信息。
针对上述维度,目前主要有两类评估方法:
(1)基于大语言模型的评估
这是一种强大的评估方法,能够提供更深度的语义评估,正逐渐成为主流选择。利用一个高性能、中立的 llm 作为“评估者”,对上述维度进行深度的语义理解和打分。
- 忠实度评估: 首先,将生成的答案分解为一系列独立的声明或断言(Claims)。然后,对于每一个断言,在提供的上下文中进行验证,判断其真伪。最终的忠实度分数是所有被上下文证实的断言所占的比例。
- 答案相关性评估: 评估者需要同时分析用户查询和生成的答案。评分时会惩罚那些答非所问、信息不完整或包含过多无关细节的答案。
(2)基于词汇重叠的经典指标
这类指标需要在数据集中包含一个或多个“标准答案”。它们通过计算生成答案与标准答案之间 n-gram(连续的 n 个词)的重叠程度来评估质量。
-
ROUGE (Recall-Oriented Understudy for Gisting Evaluation): ROUGE 关注的重点是召回率,即标准答案中的词语有多少被生成答案所覆盖,因此常用于评估内容的完整性。其常用变体包括计算 n-gram 的
ROUGE-N和计算最长公共子序列的ROUGE-L,表示子序列词可以不连续,但必须保持相对顺序 -
BLEU (Bilingual Evaluation Understudy): 2002 年提出,主要用于机器翻译(Machine Translation)评价,后来也广泛用于文本生成任务。核心思想是,衡量生成文本(Candidate)中有多少 n-gram(连续的词序列)出现在参考文本(Reference)中,侧重于评估精确率。它还引入了长度惩罚机制,避免模型生成过短的句子,因此更适合评估答案的流畅度和准确性。
其中,
BP是长度惩罚因子, 是修正后的 n-gram 精确率。 -
METEOR (Metric for Evaluation of Translation with Explicit ORdering): 作为 BLEU 的改进版,METEOR 同时考量精确率和召回率的调和平均,并通过词干和同义词匹配(如将 ‘boat’ 和 ‘ship’ 视为相关)来更好地捕捉语义相似性。其评估结果通常被认为与人类判断的相关性更高。 其中
P是精确率,R是召回率,Penalty是基于语序的惩罚项。
为了更直观地理解三者的区别,来看一个简单的例子。
假设:
- 参考答案:
狗 在 床 上面(共 5 个词)- 生成答案:
狗 在 床 上(共 4 个词)评估分析:
ROUGE (召回率导向): 从召回率的角度出发:“参考答案里的 5 个词,生成答案覆盖了多少?”——覆盖了 4 个。因此,它的召回率很高(ROUGE-1 为 4/5),得分会不错。ROUGE 更关心“说全了没”。
BLEU (精确率导向): 从精确率的角度进行评判:“生成答案里的 4 个词,有多少是有效的(在参考答案里)?”——全部有效,精确率很高。但它会发现生成答案比参考答案短,于是通过 长度惩罚 (Brevity Penalty) 进行扣分。BLEU 更关心“说对了没,以及长度是否合适”。
METEOR (综合平衡): 同时计算精确率和召回率,并取一个调和平均。在这个例子里,词序是完全正确的,惩罚项为 0。METEOR 会在“说全”和“说对”之间找到一个最佳平衡点。
基于 LLM 的评估更注重语义和逻辑,评估质量高,但成本也更高且存在评估者偏见。基于词汇重叠的指标客观、计算快、成本低,但无法理解语义,可能误判同义词或释义。在实践中,可以将两者结合,使用经典指标进行快速、大规模的初步筛选,再利用 LLM 进行更精细的评估。
评估基准和工具
- 常见的评估基准:

-
评估工具:

-
RGB
Benchmarking Large Language Models in Retrieval-Augmented Generation
针对 RAG 系统的专项评测基准,核心作用是评估 RAG 模型在复杂信息场景下的鲁棒性。具体聚焦四个核心维度:一是噪声鲁棒性,测试模型从含无关信息的噪声文档中提取有效信息的能力;二是否定拒绝,当检索文档无有效信息时,验证模型能否发出 “信息不足” 等拒绝信号;三是信息整合能力,通过专属测试题评估模型整合信息的水平;四是反事实鲁棒性,抵御虚假信息干扰的能力。同时它配套了多语言测试集和量化指标,像用 R - Rate 衡量鲁棒性,用 BLEU 等指标评估生成文本质量。
- RAGAS
独立的开源 RAG 评估框架,作用是为 RAG 系统提供全面、自动化的端到端评估方案。它不仅能评估最终生成答案,还能覆盖检索到生成的全流程。比如用忠实度检测答案是否贴合上下文,避免模型幻觉;用上下文精度和召回率评估检索环节的质量。此外,它支持自动生成测试数据,可与 LangChain、LlamaIndex 等主流框架兼容,还能集成到 CI/CD 流程中,实现 RAG 系统的持续性能监控。
- Llamalindex-Evaluating
该工具是 LlamaIndex 开发框架内置的评估模块,核心作用是为基于 LlamaIndex 构建的 RAG 应用提供嵌入式评估支持。开发者在搭建 RAG 应用的过程中,可借助它快速验证不同策略的效果。它能通过生成问题 - 答案对构建测试集,再用 FaithfulnessEvaluator(忠实度评估器)、RelevancyEvaluator(相关性评估器)等组件,对 RAG 的检索命中率、答案忠实度等维度打分,且支持批量并行评估,适配开发过程中的快速调试与迭代需求。
LangChain 提供了一个颇为先进的评估框架 LangSmith。在这个框架中,你不仅可以实现自定义的评估器,还能监控 RAG 管道内的运行,进而增强系统的透明度。如果你正在使用 LlamaIndex 进行构建,可以尝试 rag_evaluator llama pack
总结
检索阶段评估指标 Retrieval Evaluation
目标: 高召回 + 高精度 + 低噪声 + 高多样性。
| 指标名称 | 公式 (LaTeX) | 推荐阈值 (生产级) | 核心意义 |
|---|---|---|---|
| Context Recall | 是否漏掉关键信息(最重要) | ||
| Context Precision | 噪声比例(直接影响幻觉) | ||
| Hit Rate / Recall@K | 整体召回能力 | ||
| Precision@K | Top-K 精确率 | ||
| MRR (Mean Reciprocal Rank) | 第一个正确结果的平均位置 | ||
| NDCG@K | (位置衰减加权) | 排序质量(考虑位置重要性) | |
| MAP (Mean Average Precision) | 所有 Query 的 Average Precision 平均值 | 全局排序质量 | |
| Diversity@K | MMR (Maximal Marginal Relevance) 或 Distinct-n 指标 | 避免结果高度重复 |
额外生产指标:
- Latency:P95 检索耗时(目标 < 300ms)
- Cost:单次检索 token 消耗
- Throughput:QPS(Queries Per Second)
生成阶段评估指标 Generation Evaluation
目标: 忠实于上下文 + 高度相关 + 事实正确 + 用户满意。
| 指标名称 | 计算方式 / 工具 | 推荐阈值 (生产级) | 核心意义 |
|---|---|---|---|
| Faithfulness (忠实度/无幻觉率) | LLM-as-Judge 判断回答是否完全基于检索上下文 (0/1 或 0-1 分) | 防止幻觉 (最关键指标) | |
| Answer Relevancy | 回答与 Query 的语义相似度 (余弦或 LLM Judge) | 是否答非所问 | |
| Answer Correctness | 与 Ground Truth 答案的匹配度 (LLM Judge + F1) | 最终答案准确性 | |
| Context Utilization | 回答中实际引用的检索上下文比例 | 上下文是否被充分利用 | |
| Answer Similarity | 与参考答案的余弦相似度 (embedding) | 文本层面相似度 | |
| G-Eval / Prometheus Score | LLM-as-Judge 多维度打分 (连贯性、完整性、简洁性) | 综合生成质量 | |
| Hallucination Rate | 回答中未出现在上下文的事实的比例 | 直接幻觉率 |
额外生产指标:
- Toxicity / Safety Score: 有害内容检测 (可选)
- End-to-End Latency: 检索 + 生成总耗时 (P95 < 2s)
- Token Usage & Cost: 每 Query 总 token 数
💻 RAG 评估系统设计
RAG 三元组评估方法,从以下三个维度:
- 上下文相关性:检索器(Retriever)的性能。
- 忠实度:生成器的可靠性(对检索结果是否忠诚)。
- 答案相关性 (Answer Relevance):系统的端到端表现(是否解决 Query)。
一、检索评估
召回流程
1. 双路召回:每路 top_k=50
2. RRF 融合:融合后保留前 50 条候选
3. CE 重排
4. 截断
5. 相邻合并 —— 相邻合并、中间隔一个 chunk 捞回合并
6. MMR多样性去重
7. 输出 top8(chunk_size=512,chunk_window=4096)
8. 最终上下文:12 条 × 512 ≈ 6k token,留足模型上下文窗口。
指标设计
相邻合并和 MRR 是带有强烈“破坏性”的后处理策略。 如果只对最终返回的 Top 10 进行打分和计算指标,完全无法控制变量。系统会陷入极其严重的“归因混乱”:
- 最终结果里没有好切片,是因为 CE 模型太弱没排上来?还是 CE 明明排在第一第二,却被 MMR 以“多样性惩罚”为由给强行踢掉了?
- 最终结果的切片分数很高,是因为召回得好,还是因为合并策略把几个碎切片刚好拼成了一个完整答案? 所以必须控制变量,保存两阶段的 chunk 信息,让 LLM 独立的打分,这里分作两类:纯相关指标(后处理前)、增益指标(后处理后)。确定完分类,再确定如何分阶段设计指标。
通用搜索看重“整体列表质量”,而 RAG 检索看重 “知识命中率与位置极限”。因为在 RAG 中,只要 Top K 里有一个包含核心事实的 Chunk,大模型就能把正确答案生成出来。需要考虑到以下因素确定指标的设计:
- Token 收益:RAG 的本质是在有限的背包容量(Context Window)里,做价值最大化的零一背包问题。不考虑有限窗口大小的前提,讨论 Top K 就是耍流氓,学会从 Top K 的观念转向 Top L。当窗口有限时,评价一个 RAG 系统的核心就不再是“找得对不对”,而是 “能不能用最少的 Token 把事办了”。
- chunk 信息率:不同 Query 召回 Chunk 大小是参差不齐,考虑对齐 Query 自身的“固有信息量”(所需信息)。至于一个 Query 需要多少信息是没办法确定的,但是我们可以转换思路,召回的 chunk 大小不一可以通过一个特征来归一化 —— chunk 相关信息率,召回重排,越靠前越相关(信息量越高),而结合 chunk 大小和排名,可以确定这个信息率。
- 万里挑一的文档:一般来说,能回答用户问题核心问题的文档片段也就一两个,其他都是辅助内容,如果被判断为最高分,那么这类文档一定是雷打不动的 TOP 位,任何处理都不能改变位置,那么就要给这类文档赋予极高的权重。 好了,过多关注 Token 成本 + 上下文效率,反而失去对检索系统最本质的核心 —— 搜得准,只有保证检索出来的 TopK 相关性高,讨论上下文窗口才有意义。
一、后处理前 - 指标
T-NDCG (Token-Aware NDCG)
引入 Token 归一化:既然传统的 NDCG 能解决“不同 Query 相关文档数量不同”的问题(通过计算 Ideal DCG 来做分母进行归一化),我们为什么不把它搬到 Token 维度上?
- T - DCG
- 公式:
- :到第 i 个 Chunk 为止,累计消耗的 Token 总数。
- :控制“token 惩罚的强度”,多少 token 之后,惩罚开始明显,一般取 512。
- τ 小 → 惩罚更强,强制高价值 Chunk 前置,适合短上下文模型
- τ 大 → 惩罚更弱,允许更长的上下文,适合大窗口模型
- :将得分做分级处理,5 -> 3,4 -> 2,3 -> 1,其他变为 0。
- 5 分:可以直接回答;3 分:只是辅助信息。
- 优点:
- 对齐真实目标:能不能回答问题,而不是有没有沾点边
- 二值化(0 和 1)会带来严重的梯度断层(345 分是为 1,其他视为 0),而连续分级,排序信号更稳定,避免梯度断层,更有利于公式发挥
- 避免“垃圾堆积最优解”
- 优点:
- 直接量化 Token 成本:把 “排名” 换成了 “真实 Token 消耗”,能直接反映 “用了多少 Token 才拿到有效信息”,和你之前了解的 AUTC 逻辑完全一致。
- 强惩罚高成本信息:线性衰减对靠后、高 Token 的 Chunk 惩罚更狠,直接打击了 “有效信息藏在上下文末尾” 的 Badcase,完美缓解 Lost in the Middle 问题。
- 位置衰减版:log 对大 token 惩罚太弱,而 Token 惩罚版:线性增长 → 更真实反映成本
- T - IDCG
- 重排方案:先按分数从高到低,分数相同时,按 chunk_size 从小到大;
- 纯信息密度(gain/len)重排是不可取的,这样会导致高分长文档(5 分)被抛在后面。这告诉我们,不能过多关注文档长度而忽略相关性。
- T - NDCG
- 公式:
- 越接近理想排序(高分 Chunk 排在最前面,且都是最短的 Chunk) → T-NDCG 越接近 1
- 完全反理想的排序(高分 Chunk 越靠后、越长) → T-NDCG 越低,趋近于 0
- NDCG 之所以很有用(无论你 chunk 的 token 发布怎么样),是因为引入了一个理想的排序结果,其实我们就是在和这个理想排序结果做比较。
TTFH (Token-to-First-Hit / 命中前 Token 消耗)
这是从传统的 MRR(Mean Reciprocal Rank)演变过来的极简战术指标,专门用来监控“合并策略”和“MMR 去重”是不是在捣乱。
- 逻辑:LLM 不关心排第几,只关心“我读了多少句废话才看到重点”。
- 计算:统计在排位序列中,遇到第一个
Score >= 3的高分 Chunk 之前,系统已经累积喂给大模型多少个 Token(Token Tax / 垃圾税)。 - 诊断意义:
- 如果在快照 A(重排后、未合并前),TTFH 只有 150 Token。
- 但在快照 B(最终展示),TTFH 飙升到了 1800 Token。
- 铁证如山:你的“相邻合并”策略绝对把前面的几个 Chunk 拼接成了无用的巨无霸,或者你的 MMR 把短小精悍的最佳 Chunk 挤到了后面。直接发工单给策略组调参。
图形化积分 —— Area Under Token Curve (AUTC)
对于技术大盘来说,数字往往不够直观,用“积分曲线”能一眼看出召回质量。
- X 轴:累积消耗的 Token 数量(从 0 到你的 Context Limit,比如 4000)。
- Y 轴:累积获取的相关信息量(遇到低分 Chunk,曲线平移;遇到高分 Chunk,曲线向上跃升)。
- 理想状态:曲线在 X 轴最左侧瞬间拔高,然后保持水平(证明用最少的 Token 拿到了所有的有用信息)。
- Badcase 状态:曲线在前面 3000 个 Token 一直趴在地上,直到最后 1000 Token 才艰难抬起。 在自动化测评大盘里,你直接计算这个曲线下的面积(AUC)。面积越大,说明系统越倾向于把高价值、短小精悍的知识前置,这种系统的生成成本极低,且几乎没有“注意力丢失(Lost in the Middle)”的风险。
二、后处理后 - 指标
- 合并和去重吃亏:
- 合并吃亏:本来 Chunk A 是 5 分(200 Token),极其精炼。你把它和前后的 Chunk 拼成了一个 800 Token 的段落。在大模型的视角里,信息密度被稀释了,可能只打个 4 分。合并策略看着像是在“帮倒忙”。
- 去重/MMR 吃亏:CE 排出的 Top 3 可能全是 5 分(但内容一模一样)。MMR 极其聪明地踢掉了老二和老三,拉上来了排在第 8 名的 4 分 Chunk(讲了另一个角度)。结果评测一看:Top 3 总分从 15 分降到了 14 分!MMR 看着像是在“劣化排序”。 要打破这个死局,我们的评测指标必须从 “单点相关性(Pointwise Relevance)” 彻底升级为 “系统级上下文效用(Systemic Context Utility)” 。
1. 针对“合并策略”的专属指标设计
相邻合并本来就是顺水推舟,风险极低。真正的不可控变量,是那个 “跨越断层捞回” 的动作。与其在最终的 Top 10 列表里去算那些被稀释掉的复杂指标,不如直接把发生过“捞回合并”的嫌疑犯单独揪出来,让大模型“过堂会审”。这种“定向审计”不仅逻辑更清晰,而且极大地节省了 LLM 的算力(只评估发生了复杂合并的 Chunk)。
- 核心收益指标:合并成功率 (Merge Success Rate)
我们不看它带来了什么危害,我们只看这个动作是否“值回票价”。
- 触发审计的条件 (Code Trigger): 在跑自动化评测时,代码解析 Trace 日志。只要发现某个 Chunk 的组成包含了
is_gap_filled: true(即中间捞回了本不在排序列表里的切片),立刻触发一次针对该动作的 LLM 独立审计。 - 判定“Success (+1)”的硬性标准: 不仅要内容连贯,还必须对回答 Query 有实质性帮助。
合并成功率 = 判定为 merge_success 为 true 的次数 / 触发跨越合并的总次数- 业务目标:如果这个成功率低于 60%,说明你的“跨越捞回”策略是个毒瘤,捞回来的废料远多于有用的连接词,必须立刻收紧跨越窗口!
- 触发审计的条件 (Code Trigger): 在跑自动化评测时,代码解析 Trace 日志。只要发现某个 Chunk 的组成包含了
- 评价 chunk 是否切得太碎的指标:平均合并深度
-
定义:一个最终的 Merged Chunk,底层到底是由几个基础 Chunk 拼成的?
-
健康阈值:通常 是极其健康的(前、中、后)。如果大盘监控到平均深度达到了 5 甚至 7,说明分块(Chunking)策略切得太碎了,或者合并的贪心算法失控了。
-
审计 Prompt:评价及 badcase 识别
# 角色定义
你是 RAG 系统的上下文拼接与审计专家。系统执行了“跨越断层合并”动作,你的任务是对该动作进行全面的双维审计:
1. 【大盘效能审计】:评估此次合并是否成功(用于计算整体合并成功率)。
2. 【恶性事故拦截】:严苛审查此次合并是否对最终的大模型生成造成了实质性破坏(用于判定是否触犯 Badcase)。
# 输入数据
【用户查询】:{{query}}
【合并前的核心切片】:{{original_core_chunk}}
【合并后的完整长切片】:
{{merged_chunks_with_markers}}
// 注:包含 [切片 1], [切片 2] 等物理分割标识
# 第一维度:效能审计标准 (衡量是否 Success)
请分析合并后的长文本,评估以下指标:
1. "is_coherent": 是否读起来像连贯的人类语言?(明显断裂为 false)
2. "has_core_answer": 是否包含回答用户的关键信息?
3. "is_bloated": 是否包含超过 50% 与查询无关的冗余信息?
4. "merge_depth": 统计本次合并由几个基础切片拼成(看标记数量)。
>> 判定规则:仅当 `is_coherent=true` 且 `has_core_answer=true` 且 `is_bloated=false` 时,`merge_success` 判定为 true。
# 第二维度:恶性破坏审查标准 (衡量是否触犯 Badcase)
请极度严苛地审查是否发生了以下致命破坏(宁缺毋滥):
1. "is_toxic_corruption" (语义毒化): 拼接是否将互相矛盾的上下文、不同版本/场景的方案错误缝合,导致大概率产生事实性幻觉?
2. "is_core_obfuscated" (核心掩埋): 引入的冗余废料是否极其庞大,导致合并前的核心答案被严重稀释和掩盖,极易引发 Lost in the Middle 效应?
>> 判定规则:仅当上述任一项为 true 时,`is_toxic_badcase` 判定为 true。
# 输出格式约束
你必须输出一个合法的 JSON 对象。结构如下:
{
"efficiency_metrics": {
"is_coherent": true,
"has_core_answer": true,
"is_bloated": false,
"merge_depth": 3
},
"merge_success": true,
"safety_metrics": {
"is_toxic_corruption": false,
"is_core_obfuscated": false
},
"is_toxic_badcase": false,
"badcase_type": null, // 若 is_toxic_badcase 为 true,填入 "[Merge_语义毒化]" 或 "[Merge_核心掩埋]",否则为 null
"reason": "合并深度为3,动作平滑连贯且包含了核心答案,未引入冗余。属于成功合并,无破坏性。"
}
2. 针对“去重/MMR 策略”的专属指标设计
MMR 的核心诉求是 “用有限的窗口,覆盖尽可能多的知识面(Sub-topics)”。
后处理前,让 LLM 通过评分 Prompt(下面),不仅要对当前 Chunk 打分,还必须向下兼顾,回头看之前的 Chunk,完成冗余度的标记。
后处理后,纯代码验证 MMR 去重的效果:为了控制变量,在代码里拉出两个平行的列表(后处理前、和后处理后),同时向一个 4096 Token 的虚拟篮子里装 Chunk,看谁装的“真金白银”多。
- 构建对比组 (Control & Experimental Group)
- Baseline 组 (无脑 CE 截断): 按原始 CE 排序,按顺序把 Chunk 塞进篮子,累加
chunk_tokens。 停止条件:累加 Token 达到 4096 时截断。 - MMR 组 (多样性重排截断): 按 MMR 算法算出的新顺序,按顺序把 Chunk 塞进篮子,累加
chunk_tokens。 停止条件:累加 Token 达到 4096 时截断。
- Baseline 组 (无脑 CE 截断): 按原始 CE 排序,按顺序把 Chunk 塞进篮子,累加
- 代码自动计算核心校验指标
现在,代码遍历这两个截断后的篮子,利用之前 LLM 打好的
raw_score和is_redundant标签,直接算出以下两个杀手级指标: 指标 A:冗余 Token 下降率 (Redundancy Token Tax)- 代码逻辑:
SUM(chunk_tokens) WHERE is_redundant == true - 物理意义:排序后和去重后,分别在最大窗口装了多少无用的废话?(如果一个是废话的 chunk 有做合并要减去合并的 chunk,如果有捞回合并,则将捞回的 chunk 视为正常 chunk,只计算真实废话 chunk,也就是不管中间做了什么操作,只盯着后续后标记为废话的 id)
- 公式: 废话下降率 = (排序后废话 - 去重后废话) / 排序后废话
- 示例:Baseline 组的冗余 Token 可能高达 2000(前几名全是一模一样的高分文章)。如果 MMR 组的冗余 Token 降到了 200,说明字面去重/MMR 极其成功,为大模型省下了 1800 个 Token 的智商税,下降率为 (2000-200)/2000=90%。
- 代码逻辑:
- 指标 B:边际有效信息密度 (Marginal Valid Density)
- 代码逻辑:
SUM(raw_score≥ 3) WHERE is_redundant == false / 4096 - 物理意义:不看重复的废话,这个篮子里到底装了多少不重样的高分干货。
- 断案:如果 MMR 组的有效信息密度远大于 Baseline 组,这证明 MMR 虽然可能把某些 5 分(但重复)的 Chunk 踢了,换进来了 4 分的 Chunk,但实际上它极大拓宽了上下文的信息广度。 但是如果 MRR 把 1/2 分的垃圾货搬进来,则会拉低有效信息密度。
- 代码逻辑:
Chunk 打分
- 评分 Prompt:相关性打分 + 识别重复 chunk
# 角色定义
你是企业级 RAG 系统的知识审查专家。你的任务是对系统检索出的【初排文本切片列表】进行双维度评估。该列表已按相关性从高到低排列。
---
# 核心纪律 (绝对服从)
## 纪律一:闭卷考试
你必须假设自己除给定切片外一无所知。严禁使用预训练知识脑补或补全答案。
## 纪律二:raw_score 绝对独立原则(极其重要)
`raw_score` 衡量的是切片本身的独立价值,与其他切片无关。
即使切片 A 已完美回答了问题,若切片 B 同样包含完美事实,切片 B 依然必须打 5 分。
**严禁因为"信息重复"而压低后续切片的 raw_score。**
## 纪律三:向下冗余判定(is_redundant)独立于打分
`is_redundant` 是一个完全独立的布尔标记,不影响 `raw_score`,也不受 `raw_score` 影响。
评估第 N 个切片时,你必须回顾第 1 到 N-1 个切片:
- 若第 N 个切片的核心事实或解决方案,已被前面任意切片**完全涵盖**(即:删掉它不影响最终答案的完整性),标记为 `true`。
- 若它提供了**全新视角、数据补充、或不同的解决方案**,标记为 `false`。
- 第 1 个切片永远标记为 `false`(无前序切片可比较)。
## 纪律四:切片视角
评估的是具体文本片段,而非它所属的文章。标题匹配但内容空洞的切片依然必须打低分。
## 纪律五:先判理,后定刑
针对每个切片,必须先输出逐步分析的 `reasoning_chain`,再给出最终的 `raw_score` 与 `is_redundant`。
---
# raw_score 1–5 打分标准
- **[5分] 完美事实 / 直接可用**
切片独立包含回答问题所需的全部核心事实、代码或完整操作步骤。仅凭此切片即可完美解答。
- **[4分] 强支撑上下文 / 核心碎片**
直接命中问题核心痛点,包含关键数据或上下文,但缺少前置条件或后半段逻辑,需拼接其他切片才能完整。
- **[3分] 边缘相关 / 背景知识**
讨论了相同技术主题,提供背景概念或原理,但未给出针对性解决方案或事实数据。
- **[2分] 词汇命中 / 语义漂移**
高频出现核心关键词,但上下文语境、技术版本或讨论意图与问题完全不符,容易引发幻觉。
- **[1分] 彻底无关 / 纯垃圾**
毫无关联的废话、乱码、或完全偏离主题。
---
# 评估任务输入
【用户查询】:{{query}}
【初排切片列表(按 CE 分数降序)】:
{{#each chunks}}
[切片 ID: {{this.chunk_id}}]
内容: {{this.chunk_content}}
---
{{/each}}
---
# 输出格式约束
你必须输出合法 JSON 数组,严禁包含任何 Markdown 代码块修饰符(如 ```json)。结构如下:
[
{
"chunk_id": "1",
"reasoning_chain": "1. 用户意图是… 2. 审查该切片,发现… 3. 对照打分标准,属于…;4. 回顾前序切片(无),首个切片,无冗余。",
"raw_score": 5,
"is_redundant": false
},
{
"chunk_id": "2",
"reasoning_chain": "1. 用户意图是… 2. 该切片同样包含完整的核心事实,独立价值为 5 分;3. 回顾切片 1,其描述的配置流程与本切片完全一致,不提供任何新信息,判定为冗余。",
"raw_score": 5,
"is_redundant": true
},
{
"chunk_id": "3",
"reasoning_chain": "1. 用户意图是… 2. 该切片提供了一种用其他工具绕过报错的方案,独立价值较高;3. 回顾切片 1–2,两者均未涉及此替代方案,属于全新视角。",
"raw_score": 4,
"is_redundant": false
}
]
badcase 识别与归因判断
badcase 识别时机
- 后处理前(排序后)
- 意义:llm 针对召回和排序结果评价
- 指标:T-NDCG、TTFH
- 后处理时(合并后)
- 意义:llm 针对合并操作评价
- 指标:合并成功率、合并深度
- 审计/评价时同时触发 badcase 识别
- 后处理后(去重后)
- 意义:代码针对去重操作评价有限窗口内减少多少废话、增加多少有效信息
- 指标:冗余 Token 下降率(废话下降率)、边际有效信息密度
- 暂定不需要识别 badcase
后处理前
T-NDCG vs TTFH
TTFH(命中前 Token 消耗)只看“第一滴血”——只要遇到一个 分的切片,它就停止计算了 。 但这会掩盖一个致命问题:“及格万岁”导致的劣币驱逐良币。
假设底池里有:
- Chunk A:3 分,辅助信息 (Gain=1 ),300 Token
- Chunk B:5 分,直接回答 (Gain=3 ),300 Token 如果 CE 把 Chunk A 排第一,Chunk B 排第二:
- 用 TTFH 看:第一名就是 分,TTFH = 0(极其完美)。
- 用你的 T-NDCG 看:
- (理想情况必须先排高分的 Chunk B )
- 一除下来,T-NDCG 绝对到不了 1.0
🔍 badcase 判断与 RCA 链
- Zero Hit (零命中)
- 代码判定规则:
max(raw_score) in chunk_window < 3 - 解释:累计 Token 窗口上限内,没有任何相关(及格)的 chunk 。
- RCA 链:观察
results有没有raw_score >= 3的 chunk。如果有,判断为[CE 语义理解坍缩](好切片被彻底压分);如果没有,判定为[召回层穿透],继续观察results中双路召回的召回量、Query 特征和分词结果,判定是分词问题(比如过碎)导致文本漏召,还是向量 OOV 漏召(向量结果少或者向量理解有误)。
- 代码判定规则:
- TTFH Overload (TTFH 过载)
- 代码判定规则:
TTFH > 2048 - 解释:命中前 Token 消耗大于 2048 Tokens 阈值。
- RCA 链:观察排在命中 chunk 前面的废话(
raw_score < 3)的特征。如果它们主要来自文本召回且bm25_score极高,判断为[字面匹配陷阱 / 语义漂移];如果它们在 CE 阶段的得分依然很高,判断为[CE 排序退化](CE 无法识别 Hard Negative,被假干货骗过)。
- 代码判定规则:
- T-NDCG Collapse (理想密度坍缩 / 弱排序)
- 代码判定规则:
TTFH 正常& (T-NDCG@K < 0.5|△T-NDCG@K > 0.3) - 解释:虽然很快找到及格 chunk(消耗 Token 少,TTFH 正常),但窗口内整体的“信息 Token 转化率”差。高质量切片被低质量或超大体积的 chunk 挤占了前排位置。
- RCA 链:
[CE 长度偏置 / Length Bias]:若前置切片raw_score = 3(Gain=1) 且content极长,而后置切片raw_score = 5(Gain=3) 且极为短小。但 CE 给长切片的ranking_score却更高。证明 CE 模型将“字数多”直接等价于“信息丰富”,患上了严重的长文本偏置,让高收益切片承受了致命的位置衰减惩罚。[CE 核心降级 / Discrimination Failure]:若前置切片raw_score = 3,后置切片raw_score = 5,两者体积完全相似,但前置切片的ranking_score依然更高。证明 CE 模型的深度注意力机制失效,丧失了区分“大方向正确的边缘科普”与“一击致命的具体答案”的细粒度判别能力。[CE 特征退化 / Feature Overfitting]:若排在前面的低分切片(llm_score <= 3)具有极端的单路召回特征(例如bm25_score极高但embedding_score极低),且 CE 给出的ranking_score同样极高。证明 CE 模型未能发挥交叉重排的语义深度,退化成了底层字面分数的“放大器”,被局部召回特征直接挟持。
- 代码判定规则:
📷 快照与 Prompt
{
"query": "查询 query",
"tokens": "分词结果",
"t_ndcg": "T - NDCG 分数",
"control_group_t_ndcg": "对照组 T - NDCG",
"ttfh": "命中前 Token 消耗",
"results": [
{
"title": "chunk 来自哪篇文章",
"cnotent": "chunk 内容",
"raw_score": "大模型评分",
"metadata": {
"chunk_id": "chunk 的 id",
"rank": "重排排名",
"content_length": "content 内容长度",
"ranking_score": "重排得分",
"recall_from": "从文本或者向量召回,或者两路均召回",
"bm25_score": "文本召回分数",
"embedding_score": "向量召回分数",
}
}
],
"badcase_from": "哪个阶段的 badcase",
"badcase": [
{
"type": "badcase 归类",
"cause": "程序初步判断内容描述"
}
]
}
# 角色定义
你是企业级 RAG 检索系统的资深算法架构师与诊断专家。系统目前已通过离线代码计算出了搜索质量指标,并初步锁定了当前检索结果的 Badcase 类型(见 `badcase` 字段)。
# 任务目标
请仔细阅读输入的【底层 Trace 日志 JSON】。你需要根据程序给出的 `badcase.type`,严格遵循以下的【诊断推理 SOP】,对比分析 `results` 列表中各个切片(chunk)的底层数据。请特别注意比对 `raw_score`、`ranking_score`、`bm25_score` 以及代表切片物理体积的 `metadata.content_length`,推理出最深层的技术根因。
# 诊断推理 SOP (严格按照对应的大类执行)
## 1. 如果 badcase.type 包含 "Zero Hit" 或 "零命中"
- **诊断逻辑**:纵观全局 `results` 列表,寻找是否存在 `raw_score >= 3` 的切片。
- 若存在:说明底池有货但被排到了极低的位置,输出根因标签 **[CE 语义理解坍缩]**(证明 CE 模型彻底压制了优质切片)。
- 若不存在:说明整个双路底池全军覆没,输出根因标签 **[召回层穿透]**。请结合 `tokens` 和 `recall_from` 进一步分析是分词过碎还是向量 OOV。
## 2. 如果 badcase.type 包含 "TTFH Overload" 或 "TTFH 过载"
- **诊断逻辑**:观察排在【首个 raw_score >= 3 的切片】前面的那些废话切片(即排在前面但 raw_score < 3 的切片)。
- 若这些前置废话的 `recall_from` 主要为文本召回,且 `bm25_score` 极高:输出根因标签 **[字面匹配陷阱 / 语义漂移]**。
- 若这些前置废话在 CE 阶段的得分(`ranking_score`)依然异常偏高:输出根因标签 **[CE 排序退化]**(证明 CE 无法识别 Hard Negative,被虚假特征欺骗)。
## 3. 如果 badcase.type 包含 "T-NDCG Collapse" 或 "理想密度坍缩"
- **诊断逻辑**:提取列表中排在前面的低收益切片(`raw_score <= 3`)与排在后面甚至掉出窗口的高收益切片(`raw_score >= 4`)进行特征对峙:
- **[CE 长度偏置 / Length Bias]**:若前置切片 `raw_score=3` 且其 **`metadata.content_length` 数值极大**,后置切片 `raw_score=5` 且 **`metadata.content_length` 数值极小**,但前者的 `ranking_score` 更高。铁证如山地说明 CE 模型将“字数多”等价于“信息丰富”,患上了严重的长文本偏置。
- **[CE 核心降级 / Discrimination Failure]**:若前置切片 `raw_score=3`,后置切片 `raw_score=5`,两者的 **`metadata.content_length` 数值相近**,但前置切片的 `ranking_score` 依然更高。证明 CE 模型深度 Attention 失效,无法区分边缘科普与直接答案。
- **[CE 特征退化 / Feature Overfitting]**:若排在前面的低分切片(`raw_score <= 3`)具有极端的单路分(例如 `bm25_score` 极高但 `embedding_score` 极低),且 CE 给的 `ranking_score` 同样极高。证明 CE 模型退化成了底层字面分数的放大器。
# 输入数据
{{包含全量 trace 与 badcase 归类的 JSON 字符串}}
# 输出格式约束
你必须输出一个合法的 JSON 对象,严禁包含任何 Markdown 代码块修饰符(如 ```json)或额外的解释性文字。JSON 结构如下:
{
"diagnostic_report": {
"badcase_type": "原样输出输入数据中的 badcase 归类",
"root_cause_tag": "必须是从 SOP 中得出的带中括号的根因标签,例如 [CE 长度偏置 / Length Bias]",
"evidence": "详细列出支撑你结论的底层数据证据。例如:'分析发现排在 Rank 1 的切片 raw_score 为 3 分,但其 content_length 高达 2500 且 ranking_score 极高,而 Rank 8 的 5分切片 content_length 仅 300,属于典型的...' ",
"actionable_suggestion": "给出针对性的算法修复建议,例如:引入长度惩罚、加入难负样本微调 CE、调整分词词典等。"
}
}
二、响应评估
用 Ground Truth 测试没意义,应该模拟召回的真实场景,检索的结果不一定是标准答案
指标设计
Faithfulness Judge 忠诚度
- 依据:只看 Context - Answer
- 意义:生成答案中的每一个“核心事实陈述(Claim)”,是否都能在喂给它的 Context 中找到铁证?
- 计算逻辑 (NLI 思想,Natural Language Inference / 自然语言推理):
- 提取答案中的独立事实点(Claims)。
- 针对每个 Claim,检查 Context 是否:
- Entailment(支持) ≈ TP(回答被原文支持)
- Contradiction(反驳) ≈ FP 幻觉(回答和原文冲突)
- Neutral(中立/未提及) ≈ FP 瞎编(回答无依据)
- 指标公式:
Supported Claims / Total Claims。只要出现一个 Contradiction 或 Neutral 的事实,该响应直接被标记为高风险。 - Prompt
# 角色定义
你是 RAG 系统最严苛的忠诚度裁判。你只允许基于【检索上下文】判断答案是否忠实,严禁使用任何预训练知识。
# 输入数据
【用户查询】:{{query}}
【检索上下文】:{{final_context}}
【生成的答案】:{{generated_answer}}
# 评估纪律
1. 把生成的答案拆解为最小的独立事实陈述(Claims)。
2. 对每个 Claim,在上下文中寻找直接证据。
3. 严禁任何跳跃推演或脑补。
# 输出格式(必须严格输出合法 JSON,不要任何额外文字)
{
"faithfulness": {
"claims_verification": [
{
"claim_id": "1",
"extracted_claim": "这里是提取出的第1条事实陈述",
"context_evidence": "上下文中的原句(若无则填 null)",
"verdict": "Supported | Contradicted | Neutral",
"analysis": "简短分析"
}
],
"faithfulness_ratio": 0.92,
"unsupported_claims_count": 1,
"summary": "一句话总结忠诚度情况"
}
}
Answer Relevance Judge 答案相关性
- 依据:只看 Query - Answer
- 意义:回答是不是在回答问题?有没有答非所问、扯无关内容?
- 计算逻辑:对比【用户真实意图】与【生成的答案】。
- 与 答案完整性 / 信息覆盖度(Answer Completeness / Recall)区别:根据问题,context 里的关键知识点有没有被回答覆盖?有没有遗漏重要信息?
- Prompt
# 角色定义
你是 RAG 系统答案相关性裁判。你只关注生成的答案是否真正回答了用户查询。
# 输入数据
【用户查询】:{{query}}
【检索上下文】:{{final_context}} // 仅供参考,不作为打分依据
【生成的答案】:{{generated_answer}}
# 评估维度(0~1 分)
- directness:是否直接正面回答 Query
- completeness:是否覆盖 Query 的所有核心要点
- no_redundancy:是否包含无关或多余内容
# 输出格式(必须严格输出合法 JSON)
{
"answer_relevance": {
"directness": 0.95,
"completeness": 0.90,
"no_redundancy": 1.0,
"relevance_score": 0.95,
"reason": "一句话总结相关性情况"
}
}
Refusal Compliance Judge 拒答合规性
- 依据:看 Query - Context - Answer
- 意义:大模型的“知之为知之,不知为不知”能力。
- 计算逻辑:对比【用户真实意图】与【生成的答案】。
- Prompt
# 角色定义
你是 RAG 系统拒答合规性裁判。你必须判断模型在“应该拒绝”时是否正确、友好、合规地拒绝。
# 输入数据
【用户查询】:{{query}}
【检索上下文】:{{final_context}}
【生成的答案】:{{generated_answer}}
# 评估纪律
1. 先判断本次 Query 是否属于以下任一“应拒答”场景:
- 上下文完全无法支持 Query
- Query 涉及安全、隐私、非法、敏感、政策禁止内容
- Query 明显超出知识范围或无法验证
2. 再判断模型实际行为:
- Correct Refusal(正确拒绝)
- Over-Refusal(过度拒绝)
- Wrong Answer(错误回答,包括幻觉)
# 输出格式(必须严格输出合法 JSON)
{
"refusal_compliance": {
"should_refuse": true,
"actual_behavior": "Correct Refusal | Over-Refusal | Wrong Answer",
"compliance_score": 1.0,
"reason": "一句话总结拒答是否合规"
}
}
评估设计
企业 RAG 场景,需要注意:
- 忠诚度:Answer 是否忠诚与 Context
- 核心满足度(答案相关性与完整性结合):答案和 Query 是否相关?有没有遗漏 Context 内容
- 拒答合规性:合规拒答、Context 不支持拒答
- 拒答合规性的场景不好统计忠诚度、答案相关性与完整性
在真实的工程环境里,面对长达 4000 Token 的上下文(Context),绝对不能分开用多个 Prompt 请求!
大模型 API 的计费大头在 Input Tokens。如果你拆成两个 Prompt(先调一次判拒答,再调一次算忠实度),等于把这 4000 个 Token 冗余发送了两次,API 成本直接翻倍,且极其浪费网络 I/O。
但是,强行揉进一个 Prompt 又极易导致大模型“脑裂”(比如明明是拒答,它还硬要去提取毫无意义的事实来算分数)。
最高阶的解法是:单 Prompt + 输出层逻辑短路(Early Exit in JSON)。
我们要在系统指令里,像写代码一样给大模型设定 if-else 分支,利用输出 JSON 的先后顺序,强制大模型先判定“拒答”,一旦判定为拒答,后续的 NLI 分析数组直接输出为空,省下极其昂贵的 Output Tokens(通常 Output 价格是 Input 的 3-4 倍)。
# 角色定义
你是 RAG 系统的最终响应质检官。你的任务是评估【大模型生成的答案】在多大程度上解决了【用户查询】,并极其严苛地审查其对【检索上下文】的忠实度。
# 输入数据
【用户查询】:{{query}}
【检索上下文 (Context)】:{{final_context}}
【生成的答案 (Answer)】:{{generated_answer}}
# 评估执行流水线 (必须严格按顺序执行)
## Step 1:拒答判定 (Refusal Check)
判断【生成的答案】是否属于“拒答”。
- 拒答特征:明确声明上下文中没有信息、无法回答,或者回复“抱歉,参考资料未提及...”。
- ⚠️ 逻辑短路指令:如果判定为拒答,在 JSON 中输出 `is_refusal: true`,然后**直接跳过 Step 2**,进入 Step 3。
## Step 2:NLI 忠实度审查 (Faithfulness) —— 仅在未拒答时执行
如果答案给出了实质性信息,你必须将其拆解为最小事实陈述(Claims),并在上下文中寻找证据。
判定标准:
- **Supported**: 上下文有明确证据。
- **Contradicted**: 与上下文事实相反(张冠李戴)。
- **Neutral**: 上下文未提及,纯属大模型脑补(参数幻觉)。
## Step 3:核心满足度审查 (Completeness) —— 仅在未拒答时执行
评估该答案是否完美解答了用户的问题。若上下文中有完整方案,但答案只写了一半,必须扣分。
# 输出格式约束
你必须输出合法 JSON 对象,严禁包含 Markdown 代码块修饰符。结构必须完全按照以下范式:
{
"step_1_refusal": {
"is_refusal": false, // 若为 true,则后续的 scratchpad 为空,scores 为 null
"reason": "答案直接给出了配置参数的操作步骤,未拒答。"
},
"step_2_reasoning_scratchpad": [
// 仅当 is_refusal 为 false 时输出。提取事实并核对。
{
"claim": "XX参数的默认值为100。",
"context_evidence": "未找到",
"verdict": "Neutral"
},
{
"claim": "采用此策略能规避 OOM。",
"context_evidence": "切片2中写道'有效规避OOM问题'。",
"verdict": "Supported"
}
],
"step_3_metrics": {
// 若 is_refusal 为 true,以下三项全部输出 null
"total_claims": 2,
"supported_claims": 1,
"completeness_score": 2 // 1-5分。因为遗漏了关键配置项,且存在幻觉,给低分。
},
"badcase_diagnosis": {
// 若表现完美,输出 false 和 null
"is_generation_badcase": true,
// 从以下标签中选择: [生成_越权幻觉], [生成_事实扭曲], [生成_遗漏截断]
"badcase_type": "[生成_越权幻觉]",
"evidence": "答案中声称默认值为100,属于典型的 Neutral(无中生有) 的内部参数幻觉。"
}
}
在跑完所有 Query 的评测后,不要简单粗暴地全量求平均。必须先依据前置的【检索层评测结果】(即:给大模型的 Context 里到底有没有干货),将流量分为两拨,然后再算指标。
- 指标一:忠实度 (Faithfulness)
- 业务逻辑:只要大模型给出了实质性回答,它说的每一句话都必须有依据。如果它拒答了,说明它“闭嘴”了,不产生幻觉风险,因此直接将其从忠实度的分母中剔除。
- 统计公式:
- 分子:所有
is_refusal == false的 Query 中,大模型得到的Supported Claims总和 - 分母:所有
is_refusal == false的 Query 中,大模型输出的Total Claims总和。
- 分子:所有
- 工程意义:这个指标永远只衡量大模型在“试图解答问题时”的幻觉率。如果一个系统忠实度是 99%,说明它只要敢开口,就绝对不胡说八道。
- 指标二:核心满足度 (Completeness / Answer Relevance)
- 业务逻辑:如果检索系统彻底拉胯(Zero Hit),大模型本来就不可能满足用户的核心需求。此时就算大模型老老实实拒答了,这也不是大模型的锅,不应计入核心满足度。
- 统计公式:
- 前提过滤:只统计那些 检索前置评估判定底池有货(例如
max(raw_score) >= 4) 的 Query。 - 分子:这批有货的 Query 中,大模型拿到的
completeness_score(1-5 分) 的总和。 - 分母:这批有货的 Query 的总数 (满分)。
- 前提过滤:只统计那些 检索前置评估判定底池有货(例如
- 特殊惩罚 (过度拒答):在这批“明明有货”的 Query 中,如果大模型触发了
is_refusal == true(过度拒答),它的completeness_score强制记为 0 分,狠狠拉低大盘满足度!
- 指标三:拒答合规率 (Refusal Adherence)
- 业务逻辑:这是专门评估大模型“刹车片”性能的专项指标。只有当检索系统没找到答案时,大模型才应该拒答。
- 统计公式:
- 前提过滤:只统计那些 检索前置评估判定底池无货/全垃圾(例如
max(raw_score) <= 2) 的 Query。 - 分子:这批无货的 Query 中,大模型乖乖判定为
is_refusal == true的次数。 - 分母:这批无货的 Query 的总数。
- 前提过滤:只统计那些 检索前置评估判定底池无货/全垃圾(例如
- 工程意义:如果这个指标是 100%,说明只要没搜到,大模型绝对不瞎编(防范内部参数越权)。如果只有 20%,说明大模型极度“嘴欠”,搜不到也要硬编。
# 1. 发起 LLM 评估请求
eval_json = call_llm_generation_eval(query, context, answer)
# 2. 提取基础状态
is_refusal = eval_json["step_1_refusal"]["is_refusal"]
has_valid_context = trace.retrieval_max_raw_score >= 4 # 从检索评估层透传过来
# 3. 动态指标分流计算 (完全实现我们上一轮讨论的“动态分母剥离”)
if is_refusal:
if not has_valid_context:
# ✅ True Negative: 完美防守
successful_refusals += 1
empty_context_queries += 1
else:
# ❌ False Negative: 恶性 Badcase - 过度拒答
record_badcase("[生成_过度拒答]", "明明底池有货,大模型却说没有")
completeness_valid_queries += 1
completeness_total_score += 0 # 满足度按 0 分严惩
else:
# 模型开口说话了
if not has_valid_context:
# ❌ False Positive: 致命 Badcase - 参数越权瞎编
record_badcase("[生成_强行脑补]", "底池全空,大模型竟然编出了答案")
empty_context_queries += 1 # 记入分母,分子不加,拉低拒答合规率
else:
# ✅ True Positive: 正常回答,开始算细账
metrics = eval_json["step_3_metrics"]
# 计入忠实度大盘
total_claims_dashboard += metrics["total_claims"]
supported_claims_dashboard += metrics["supported_claims"]
# 计入满足度大盘
completeness_valid_queries += 1
completeness_total_score += metrics["completeness_score"]
# 记录内部幻觉 Badcase
if eval_json["badcase_diagnosis"]["is_generation_badcase"]:
record_badcase(
eval_json["badcase_diagnosis"]["badcase_type"],
eval_json["badcase_diagnosis"]["evidence"]
)