LangMem vs Mem0
两者解决的核心问题一样(Agent 长期记忆),但设计哲学完全不同:
| Mem0 | LangMem | |
|---|---|---|
| 定位 | 独立记忆服务,框架无关 | LangGraph 生态的记忆层 |
| 存储层 | 自带向量库 + 图数据库 | 依赖 LangGraph BaseStore |
| 短期记忆 | 自己管 | 交给 LangGraph Checkpointer |
| 召回延迟 | p95 约 200ms | p95 约 60 秒(LLM 重分析导致) |
| 记忆类型 | 语义记忆为主 | 三类:语义 + 情节 + 程序记忆 |
| 最大亮点 | 快、独立、易接入 | 程序记忆(Agent 自动修改自己的 prompt) |
最关键的区别:LangMem 有 Mem0 没有的东西——程序记忆(Procedural Memory),这是两者在设计理念上本质分叉的地方,后面重点讲。
LangMem 的三种记忆类型
1. 语义记忆(Semantic Memory)— 事实
和 Mem0 类似,存用户偏好、事实、知识。分两种形态:
# Collection:无上限,可搜索,适合积累大量事实
namespace = ("memories", "{user_id}")
# Profile:单一结构化文档(用户画像),覆盖式更新
from pydantic import BaseModel
class UserProfile(BaseModel):
name: str
preferences: list[str]
expertise_level: str
2. 情节记忆(Episodic Memory)— 经历
存”发生过什么事”,不是事实,是经历片段:
"用户上次问了量子计算的问题,但对数学公式不感兴趣,
更喜欢直觉性解释"
Mem0 也能存这类内容,但 LangMem 在概念上做了显式区分。
3. 程序记忆(Procedural Memory)— 行为规则
这是 LangMem 独有的。Agent 根据对话经验,自动修改自己的 system prompt。
初始 prompt:
"你是一个助手,请帮助用户解答问题。"
经历 10 次对话后,程序记忆 optimizer 发现:
- 用户总是要求精简回答
- 用户是工程师,不需要解释基础概念
- 用户偏好代码示例
自动更新 prompt 为:
"你是一个助手。回答要精简。
用户是有经验的工程师,跳过基础解释。
优先给代码示例,再给文字说明。"
这不是存一条记忆,是修改 Agent 的行为本身。
两种工作模式
Hot Path(同步,对话中实时)
Agent 自己决定何时存、何时查:
from langmem import create_manage_memory_tool, create_search_memory_tool
agent = create_react_agent(
"anthropic:claude-sonnet-4-5",
tools=[
create_manage_memory_tool(namespace=("memories",)),
create_search_memory_tool(namespace=("memories",)),
],
store=store,
)
LLM 自主调用这两个 tool,完全由它决定存什么、什么时候搜。问题:LLM 可能忘记调,也可能滥用,且有延迟。
Background(异步,对话结束后处理)
对话完成后,后台异步提取记忆,不阻塞主流程:
from langmem import create_memory_store_manager, ReflectionExecutor
manager = create_memory_store_manager(
"anthropic:claude-sonnet-4-5",
namespace=("memories", "{user_id}")
)
reflection = ReflectionExecutor(manager, store=store)
@entrypoint(store=store)
async def chat(messages: list):
response = await agent.ainvoke({"messages": messages})
# 对话结束后异步提取,不影响响应速度
reflection.submit(
{"messages": response["messages"]},
after_seconds=2 # debounce:用户连续对话时合并处理
)
return response
after_seconds 是一个重要设计:用户连续发消息时,不会触发多次提取,等静默 2 秒后才处理,避免重复。
程序记忆的三种 Optimizer 算法
这块是 LangMem 真正有意思的地方:
metaprompt:
整体看对话 → 反思 → 用 meta-prompt 提议修改
特点:修改质量高,但用 token 最多
gradient:
分两步:先批判(哪里不好)→ 再提议修改
类似梯度下降:每次小步优化
特点:稳定,不容易过拟合
prompt_memory(最简):
一步完成批判 + 提议
特点:快,但质量不如前两者
from langmem import create_prompt_optimizer
optimizer = create_prompt_optimizer(
"anthropic:claude-sonnet-4-5",
kind="gradient", # metaprompt / gradient / prompt_memory
)
updated_prompt = await optimizer.ainvoke({
"trajectories": [(conversation, {"feedback": "回答太啰嗦"})]
})
与 Mem0 的使用场景分野
用 Mem0 当:
- 框架无关,不想绑定 LangGraph
- 需要快速召回(实时对话,延迟敏感)
- 只需要语义记忆(用户偏好、事实)
- 需要云托管记忆服务
用 LangMem 当:
- 已经在用 LangGraph
- 需要程序记忆(Agent 自我进化)
- 需要情节记忆 + 语义记忆的完整分层
- 可以接受后台异步处理,不要求实时召回
需要重点了解的几个点
按优先级排:
1. 程序记忆 + Optimizer:LangMem 最核心的差异点,三种算法的机制和适用场景。 2. Hot Path vs Background 的选型:两种模式有根本性的延迟和可靠性取舍,生产环境几乎必选 Background。 3. LangGraph 三层记忆架构:Checkpointer(会话内短期)+ BaseStore(跨会话长期)+ LangMem(提取和优化逻辑)。三层各管什么、缺一会怎样。 4. 记忆合并(Consolidation)机制:LangMem 怎么防止记忆无限膨胀,和 Mem0 的去重方式有什么不同。 5. Namespace 设计:多用户、多 Agent 场景下的隔离方案。
提示词优化:程序记忆 + Optimizer 原理
一、程序记忆的本质
先建立正确的认知。程序记忆不是”存一条数据”,而是修改 Agent 的行为规则本身。
语义记忆:存一条事实 → "用户喜欢深色模式"
↓
下次对话时从存储里搜出来注入 context
程序记忆:分析对话模式 → "用户总是要求代码示例"
↓
直接修改 system prompt → 下次默认给代码示例
不需要搜索,行为已经内化到 prompt 里
存储位置决定了召回方式:语义记忆存在向量库里,靠相似度搜出来;程序记忆存在 prompt 文本里,每次直接生效,不需要搜索。
二、Optimizer 的输入输出
理解三个核心数据结构:
- Trajectory(轨迹) 一次对话 + 对这次对话的评价:
from langmem.prompts.types import AnnotatedTrajectory
trajectory = AnnotatedTrajectory(
messages=[ # 对话过程
{"role": "user", "content": "解释一下量子计算"},
{"role": "assistant", "content": "量子计算是利用量子力学..."},
{"role": "user", "content": "能给个具体例子吗"},
{"role": "assistant", "content": "当然,以下是一个例子..."},
],
feedback={ # 对这次对话的评价(可选)
"score": 0, # 0=差,1=好
"comment": "第一次回答太抽象,应该直接给例子"
}
)
- Prompt(待优化的提示词)
from langmem import Prompt
prompt = Prompt(
name="assistant", # 标识符
prompt="你是一个助手,帮用户回答问题。", # 当前 prompt 文本
update_instructions="只修改必要的部分", # 告诉 optimizer 怎么改
when_to_update="当回答质量不佳时", # 什么情况下该改这个 prompt
)
- OptimizerInput
{
"trajectories": [trajectory1, trajectory2, ...], # 多条对话经验
"prompt": prompt # 要优化的 prompt
}
输出:优化后的 prompt 字符串。
三、三种 Optimizer 的原理
1. prompt_memory(最简,1 次 LLM 调用)
输入:trajectories + 当前 prompt
↓
一次 LLM 调用:
"这是当前 prompt:{prompt}
这是对话历史和反馈:{trajectories}
请提取成功模式,直接输出改进后的 prompt"
↓
输出:新 prompt
- 优点:快,便宜
- 缺点:一次性处理所有信息,复杂模式容易遗漏,没有自我纠错
2. metaprompt(中等,1-5 次 LLM 调用)
metaprompt 优化器使用一个集成的提示词来引导模型完成分析和改进阶段。它不采用单独的假设和建议步骤,而是使用结构化的反思工具(think 和 critique),使模型能够在生成改进之前对提示词的有效性进行推理。
这种方法减少了计算开销,同时仍然支持多步反思。metaprompt 模板包含当前提示词、更新说明、轨迹数据的部分,以及用于识别失败模式和生成最小修复的结构化指导。

- 引入了反思循环 + 一个 Prompt + 工具控制行为:
输入: trajectories + 当前 prompt
⬇️
阶段 1:强制反思阶段(第 1 ~ min_reflection_steps 轮)
第 1 次 LLM 调用(强制反思)
→ 输出 tool_results:仅分析 / 批判结果(只能调用 `think`/`critique` 工具,不允许输出新 prompt)
⬇️
...(循环,直到完成 `min_reflection_steps` 轮)
⬇️
阶段 2:可选改写阶段(第 min_reflection_steps+1 ~ max_reflection_steps-1 轮)
第 N 次 LLM 调用(反思或改写)
→ 输出 tool_results :可选择继续反思,或直接输出优化后的 prompt(`any_chain`,工具三选一)
⬇️
...(循环,直到第 `max_reflection_steps-1` 轮)
⬇️
阶段 3:强制输出阶段(第 max_reflection_steps 轮)
第 max_reflection_steps 次 LLM 调用(强制改写)
→ 输出 tool_results :新 prompt(只能调用 `schema_tool`,强制输出结构,不能再反思)
⬇️
结束,输出最终 prompt
- 提示词
DEFAULT_METAPROMPT = """
你正在通过优化提示词,帮助一名 AI 助手进行学习。
## 背景
以下是当前使用的提示词:
<current_prompt>
{prompt}
</current_prompt>
开发者提供了关于「何时/如何更新提示词」的说明:
<update_instructions>
{update_instructions}
</update_instructions>
## 会话数据
请分析下面的会话记录(以及任何用户反馈):
<trajectories>
{trajectories}
</trajectories>
## 指令
1. 反思智能体在给定会话中的表现,识别出**真实存在的失败模式**
(例如:风格不匹配、指令不清晰或不完整、推理存在缺陷等)。
2. 建议为解决这些失败所需做出的**最小改动**。
如果提示词表现完美,直接返回原提示词,不做任何修改。
3. 必须**原样保留**现有提示词中的所有 f-string 变量
(例如 {{variable_name}} 这类格式不能改动)。
**只有在确实需要修改时**,才专注于可执行的编辑。要求具体、明确。
编辑内容必须与识别出的失败模式匹配。
例如:
- 为风格问题补充少量小样本示例
- 明确决策边界
- 为条件逻辑、规则、推理修复添加或修改明确指令
- 若模型推理能力不足,为多步逻辑问题提供分步推理指南
"""
3. gradient(最强,2-10 次 LLM 调用)
反思循环采用三个专用工具来引导模型进行系统分析。think 工具使模型能够深入推理问题的复杂性和潜在的修复方法,而 critique 工具促进对假设进行严格的自我评估。recommend 工具对是否需要进行调整做出最终决定,从而防止不必要的提示词修改。这种基于工具的方法确保了结构化推理和可复现的优化行为。
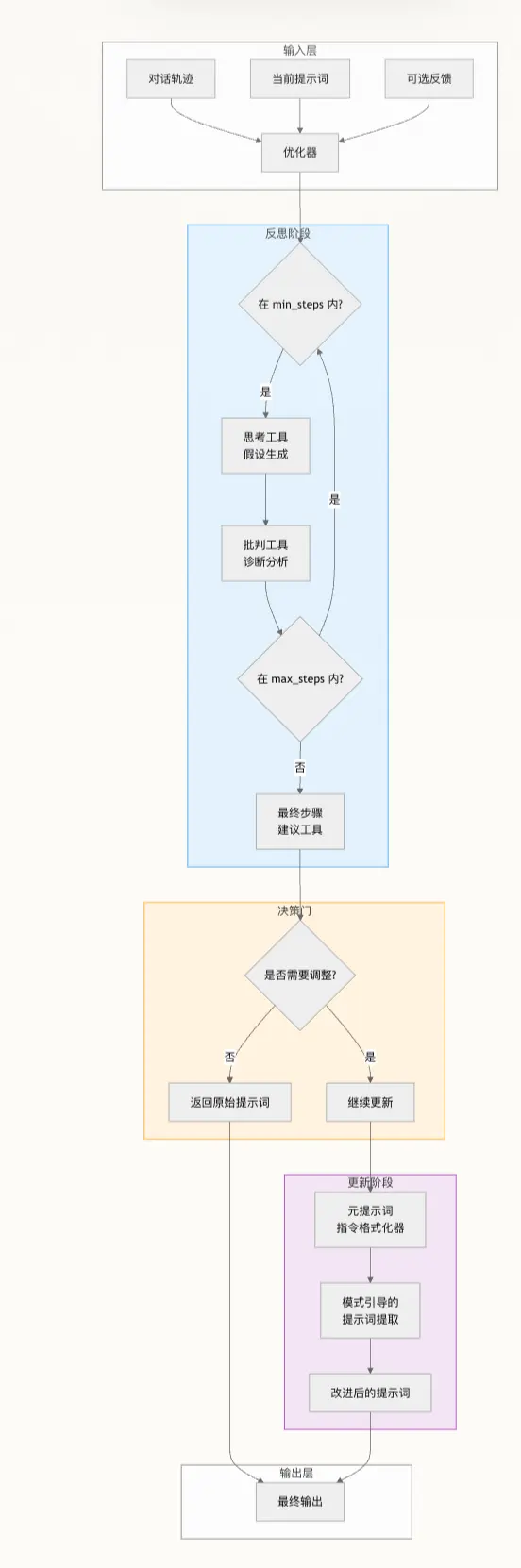 灵感来自机器学习的梯度下降。核心思想是分离关切:
灵感来自机器学习的梯度下降。核心思想是分离关切:
输入:trajectories + 当前 prompt
↓
第 1 ~ max_steps-1 步: Think/Critique(批判)
LLM A:"这个 prompt 哪里不好?为什么导致了这些糟糕的对话?"
→ 输出:详细批判报告("gradient",类比梯度方向)
↓
最后一步:Update(更新)
LLM B:拿着批判报告 + 当前 prompt
"根据批判报告,具体怎么修改 prompt?"
→ 输出:新 prompt
每个 step = 2 次 LLM 调用,所以 max_reflection_steps=5 最多 10 次调用。
为什么分离 Critique 和 Think/Update 工具更好? 合并成一步时 LLM 需要同时”找问题”和”给解决方案”,两个任务争夺注意力。分开后:
- Critique 专注深度分析,可以更苛刻
- Update 专注改写,可以更精准
四、Trajectory 的作用:有 feedback vs 没有 feedback
# 有显式 feedback:optimizer 以 feedback 为主要改进信号
trajectory = AnnotatedTrajectory(
messages=[...],
feedback={"score": 0, "comment": "回答太啰嗦"}
)
# 没有 feedback:optimizer 从对话本身推断哪里不好
trajectory = AnnotatedTrajectory(
messages=[
{"role": "user", "content": "解释量子计算"},
{"role": "assistant", "content": "量子计算很复杂..."},
{"role": "user", "content": "能说人话吗"}, # ← 这句本身就是信号
],
feedback=None
)
没有 feedback 时,optimizer 靠对话模式推断:用户追问、重复提问、表达不满——这些都是隐式的负反馈信号。
五、多 prompt 优化的额外机制
单个 prompt 优化很直接。多 prompt 优化(create_multi_prompt_optimizer)多了一步:Credit Assignment(归因)。
Agent 由三个 prompt 组成:
- research_prompt:负责调研
- reason_prompt:负责推理
- write_prompt:负责写作
对话失败了 → 是哪个 prompt 的锅?
↓
Credit Assignment LLM:
"分析这次对话,判断是哪个 prompt 导致了问题"
→ 输出:{"research_prompt": 0.1, "reason_prompt": 0.8, "write_prompt": 0.1}
(主要是 reason_prompt 的问题)
↓
只优化得分低的 prompt,其他不动
这避免了”一个 prompt 出问题,把所有 prompt 都改一遍”的过度优化。
when_to_update 字段也影响这一步:
prompts = [
Prompt(
name="vision_extract",
prompt="提取图片中的视觉细节",
),
Prompt(
name="vision_classify",
prompt="分类图片中的具体属性",
when_to_update="只在 vision_extract 更新之后才更新", # 依赖关系
),
]
optimizer 会先改 vision_extract,再决定是否改 vision_classify,保证依赖顺序。
六、优化结果怎么持久化
Optimizer 本身是无状态的纯函数——输入 trajectories + 旧 prompt,输出新 prompt 字符串。它不管存储,这是你的事:
import json
from pathlib import Path
from langmem import create_prompt_optimizer
optimizer = create_prompt_optimizer(
"anthropic:claude-sonnet-4-5",
kind="gradient",
config={"max_reflection_steps": 3}
)
PROMPT_FILE = Path("prompts/assistant.json")
# 读取当前 prompt
current = json.loads(PROMPT_FILE.read_text())["prompt"]
# 优化
new_prompt = await optimizer.ainvoke({
"trajectories": [trajectory],
"prompt": current
})
# 持久化(你自己决定存哪)
PROMPT_FILE.write_text(json.dumps({"prompt": new_prompt}))
# 下次启动时读取新 prompt 初始化 Agent
与 LangGraph Store 结合时,prompt 存在 BaseStore 里,用固定 key 读写:
from langgraph.store.memory import InMemoryStore
store = InMemoryStore(...)
# 存
await store.aput(
namespace=("prompts", "v1"),
key="assistant_prompt",
value={"text": new_prompt}
)
# 取
item = await store.aget(
namespace=("prompts", "v1"),
key="assistant_prompt"
)
current_prompt = item.value["text"]
七、选型决策
只需要快速迭代,token 预算紧
└→ prompt_memory(1 次调用)
需要稳定优化,对话模式中等复杂
└→ metaprompt(2-5 次调用)
对话模式复杂,反馈信号隐晦,需要深度分析
└→ gradient(4-10 次调用)
多个 Agent prompt 需要协同优化
└→ create_multi_prompt_optimizer(任意 kind)
p95 延迟 60 秒的来源就是 gradient 模式跑满 10 次 LLM 调用,每次还可能带长 context。如果是实时场景,用 prompt_memory 或者把优化完全放到离线 pipeline 里跑。
八、一句话总结三种算法
prompt_memory:一次看完所有经验,直接改。快但浅。
metaprompt: 看 → 反思 → 改 → 再反思 → 再改(循环)。
同一个 LLM,在同一次回答里,同时完成「反思 + 优化」
gradient: 看 → 批判(LLM A)→ 改写(LLM B)→ 循环。
两个 LLM,一个"找问题",一个"写改法"