https://zread.ai/BerriAI/litellm/3-sdk-vs-proxy-decision-guide
核心能力概览
LiteLLM 的核心价值主张:使用 OpenAI 格式编写一次 LLM 集成代码,然后只需更改模型名称前缀(例如 openai/gpt-4o anthropic/claude-sonnet-4-20250514)即可路由到任何提供商。无需重写 SDK,无需更改 API 格式,无需在代码库中分散处理身份验证逻辑。
| 能力 | 描述 | 了解更多 |
|---|---|---|
| 统一 API | 使用 OpenAI 兼容格式调用 100 多家提供商 | 快速开始 |
| 智能路由 | 跨部署进行负载均衡,支持故障转移、重试和冷却 | 路由与负载均衡 |
| 成本追踪 | 按密钥、按团队、按用户的支出追踪,提供统一的成本计算 | 成本计算引擎 |
| 虚拟密钥 | 颁发具有预算限制和权限控制的受限 API 密钥 | 身份验证与虚拟密钥 |
| 速率限制 | 按密钥、按用户、按模型的 RPM/TPM 限制 | 速率限制与预算执行 |
| 可观测性 | 50 多种集成:Langfuse、Datadog、OpenTelemetry、Prometheus 等 | 日志与回调系统 |
| 缓存 | 基于 Redis 的 LLM 响应缓存,支持双重缓存(内存 + Redis) | 缓存策略 |
| 护栏 | 内容过滤、提示词注入检测、安全策略 | 护栏与内容过滤 |
| 管理后台 | 用于管理密钥、团队、支出日志和模型配置的内置 UI | 代理服务器设置 |
| A2A 与 MCP | Agent-to-Agent 协议和 Model Context Protocol 网关支持 | MCP 与 Agent 网关 |
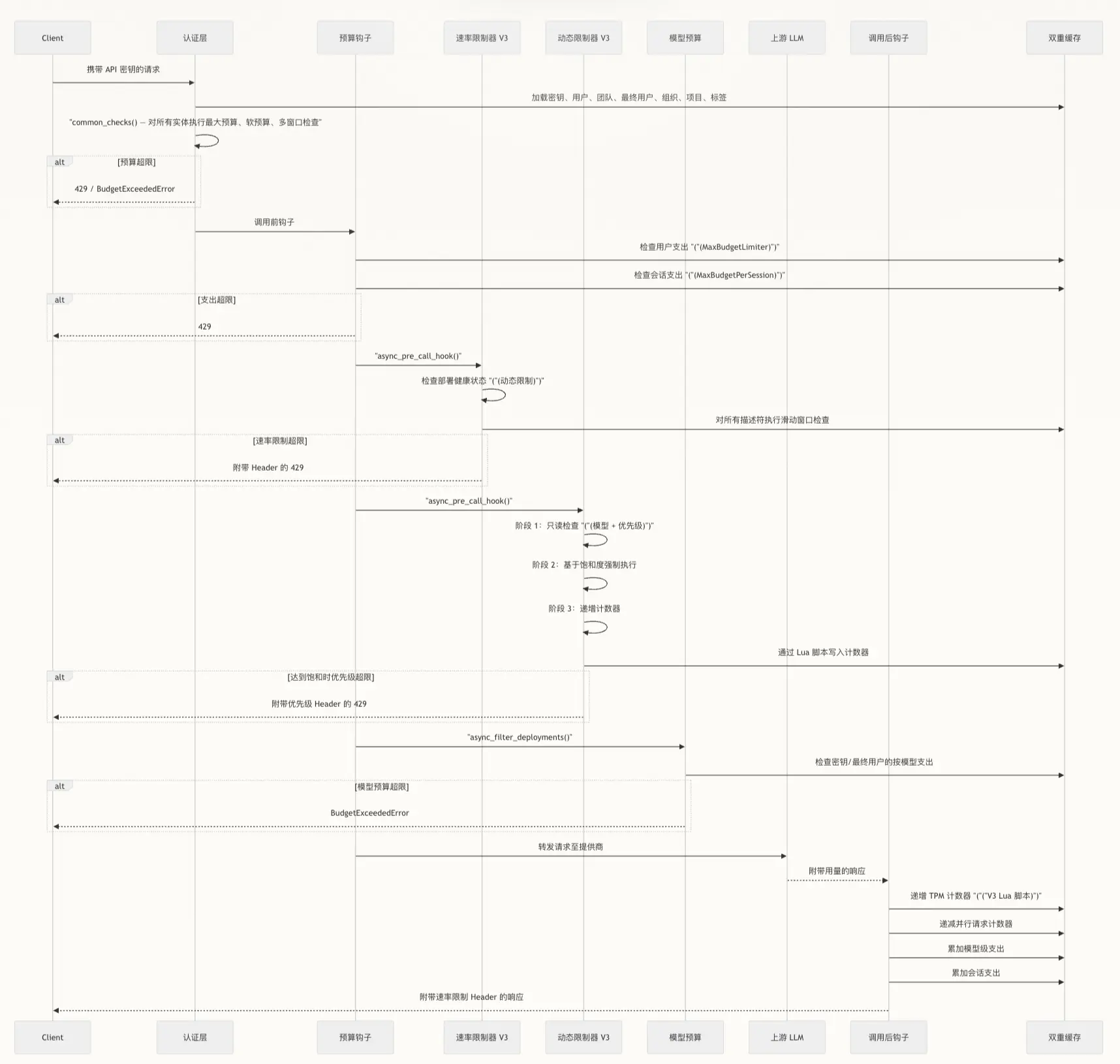
预算和速率限制
-
架构

-
请求声明周期
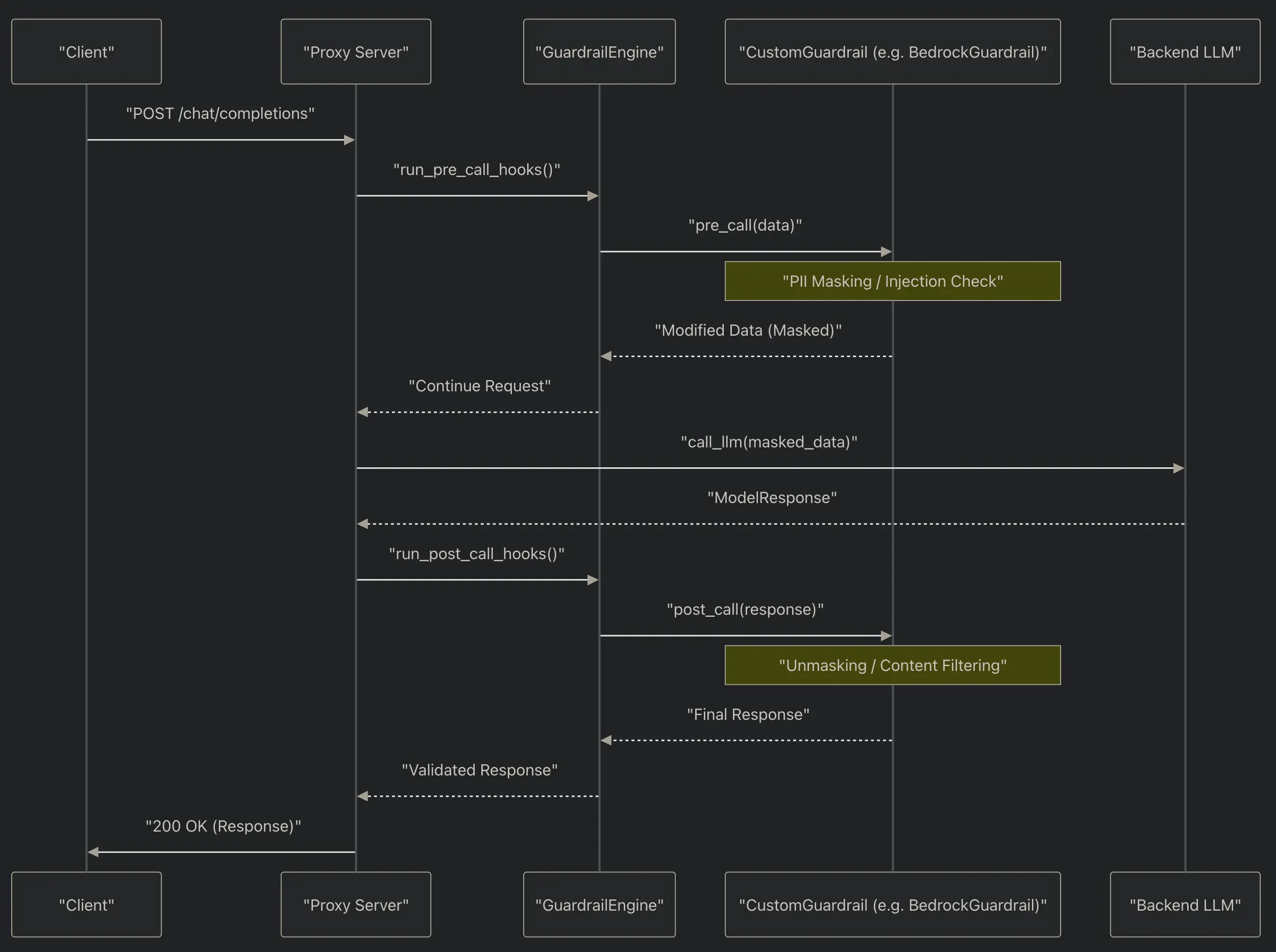
护栏
HTTP Request
│
▼
[pre_call hooks] ──► 第三方 API / 正则 / 本地规则 ──► raise Exception → 返回 4xx
│
▼
[LLM Provider Call]
│
▼
[during_call hooks] (并发,不阻塞)
│
▼
[post_call hooks] ──► 检查 response ──► raise Exception → 替换响应或返回 4xx
│
▼
Response 返回给 Client
LiteLLM 内容审核与提示词安全的实现原理
这两块功能在 LiteLLM 里的实现思路差异很大:内容审核主要靠外包给专业检测服务,提示词安全则有内置的多层检测机制。下面分别展开。
一、内容审核(Content Moderation)
1. 内置过滤器:litellm_content_filter
这是 LiteLLM 唯一不依赖外部服务的内容审核方案,完全基于正则模式和关键词匹配,无需外部依赖,也无需 ML 模型,适合不需要机器学习来检测敏感信息的场景。
它有三层检测逻辑,按优先级依次执行:
① 类别关键词匹配(最高优先级)
支持有害内容类别配置,包括 harmful_self_harm、harmful_violence、harmful_illegal_weapons、bias_gender、bias_racial 等,每个类别可以设置严重性阈值(low / medium / high)和动作(BLOCK)。类别关键词检测先于正则模式执行。
底层实现是把每个类别预置的一批关键词组成词典,逐条比对输入文本。
② 预置正则模式(PII 结构化数据)
支持预置 pattern,如 us_ssn、email、aws_access_key、visa 等,以及自定义 regex。命中后可执行 BLOCK(拦截并返回 400)或 MASK(替换为占位符后继续发给 LLM)。
③ 关键词黑名单
直接字符串匹配,命中即触发 BLOCK 或 MASK。
流式响应也会逐 chunk 检查,不会等全部内容返回后再做判断。
2. 外部内容审核服务(委托模式)
对于真正需要 ML 语义理解的内容审核,LiteLLM 的策略是把检测工作完全委托给专业外部服务,自己只负责:
- 在 pre_call / post_call 钩子中把文本提取出来
- 以 HTTP 请求发给第三方检测 API
- 根据返回的评分/标签决定是否 raise Exception 拦截
LiteLLM 支持的内容审核服务包括:IBM FMS Guardrails(检测 hate speech、jailbreaks、PII)、Javelin(提示词注入、trust & safety 违规、语言检测)、Lasso Security(有害内容生成)、Gray Swan Cygnal(持续监控策略违规)、Google Cloud Model Armor、Noma Security 等。
以 Lasso 为例,检测类别包括 jailbreak、sexual、hate、illegality、codetect(代码注入)、violence、pattern-detection,每个类别独立评分,返回 severity 和 action。
二、提示词安全(Prompt Injection Detection)
这是更有意思的部分。LiteLLM 内置了三种检测机制,通过 detect_prompt_injection callback 注册:
机制 1:Heuristics Check(启发式相似度检测)
实现在 prompt_injection_detection.py 的 check_user_input_similarity 方法中:对内置的已知攻击关键词列表(约 50~100 个),对用户输入做滑动窗口截取子串,然后用 Python difflib.SequenceMatcher 计算每个子串与关键词的相似比,超过阈值则判定为攻击。
这实际上是一个 O(n×m) 的字符串相似度暴力匹配,其中 n 是输入长度,m 是关键词数量。
值得注意的是,这个检测逻辑是同步调用,被放在 async_pre_call_hook 里直接执行,会阻塞 FastAPI 的整个事件循环,在生产环境中可能导致 K8s 健康探针超时和 pod 重启,这是一个已知的严重 bug。
此外,这种子串相似匹配会产生大量误报,例如普通单词 “submit” 就曾触发检测,导致正常请求被拒绝。
机制 2:Similarity Check(向量相似度检测)
LiteLLM 支持将用户输入与预先生成的提示词注入攻击向量库做相似度比对,来判断请求是否包含注入攻击。
原理是:离线对已知攻击 prompt 生成 embedding,存入向量库;运行时对用户输入也生成 embedding,做 ANN(近似最近邻)搜索,距离低于阈值则判定为攻击。
机制 3:LLM API Check(用 LLM 判断 LLM)
把用户输入发给另一个 LLM(可配置为任意 model_list 中的模型),以预设的 system prompt 要求它判断输入是否安全,如果返回特定字符串(如 “UNSAFE”)则拦截请求。
这是语义理解能力最强的方式,但延迟最高,且目前由于继承了错误的基类,llm_api_check 功能实际上是完全不工作的。
三、第三方专用提示词注入检测
以 Javelin 为例,它对提示词注入返回结构化评分,包括 jailbreak 和 prompt_injection 两个维度的独立评分(0~1),并给出 request_reject 的布尔判断。
以 Prompt Security 为例,检测能力覆盖:提示词注入、Jailbreak 尝试、用户输入中的 PII、恶意文件上传(含隐写术检测)、文档漏洞利用(PDF/Office 文件)、数据泄露检测。
总结对比
| 能力 | 实现方式 | 强度 | 延迟 |
|---|---|---|---|
| 结构化 PII 检测 | 内置 regex | 低(不理解语义) | 极低 |
| 关键词/类别过滤 | 内置词典匹配 | 低 | 极低 |
| Jailbreak/注入 启发式 | SequenceMatcher 滑窗 | 低(高误报) | 低但阻塞事件循环 |
| 注入 向量相似度 | embedding + ANN | 中 | 中 |
| 注入 LLM 判断 | 调用另一个 LLM | 高 | 高(且目前有 bug) |
| 语义内容审核 | 外包给第三方 API | 高 | 中~高 |
LiteLLM 本身在内容审核和提示词安全上的内置能力是非常基础的,核心价值是作为一个统一的接入层,让各种专业安全服务(Lakera、Aporia、Presidio、Bedrock Guardrails 等)能通过一套标准钩子挂入 LLM 请求流程,而不是自己实现复杂的检测模型。
缓存架构
一、整体层次
LiteLLM 的缓存逻辑主要由 LLMCachingHandler(caching_handler.py)管理,它作为核心 Cache 类(caching.py)的包装层。系统支持多种存储后端(in-memory、disk、Redis、S3、GCS、Qdrant),并通过请求参数提供细粒度的缓存控制。
所有 backend 实现都继承自 BaseCache,通过 type 参数在初始化时选择具体实现:
LLMCachingHandler ← 核心调度层
└── Cache ← 统一抽象接口
├── InMemoryCache (local)
├── DiskCache (disk)
├── RedisCache (redis)
├── RedisSemanticCache (redis-semantic)
├── QdrantSemanticCache (qdrant-semantic)
├── S3Cache (s3)
└── GCSCache (gcs)
二、DualCache:两级缓存架构
这是生产部署中最关键的设计。LiteLLM 在配置了 Redis 时使用 DualCache 策略,将 InMemoryCache 和 RedisCache 包裹成一个两级缓存系统。L1 是本地内存缓存,提供亚毫秒级查询;L2 是 Redis 分布式缓存,在多个 Proxy 实例间共享状态。
查询流程:
Request
│
▼
L1: InMemoryCache (本进程内)
├── HIT → 直接返回(<1ms)
└── MISS
▼
L2: RedisCache (跨实例共享)
├── HIT → 回填 L1,返回
└── MISS
▼
调用上游 LLM
▼
写入 L2 (Redis) + 写入 L1
这个架构对 Router 和 Proxy 鉴权系统都很重要,它们用这个双层缓存来存储 deployment 健康状态和 API key 验证结果。
三、Cache Key 生成机制
缓存 key 通过哈希输入参数生成:输入包含 model、messages/prompt 和可选参数(temperature、top_p、tools、functions 等),参数序列化为 JSON 后做 SHA-256 哈希。如果配置了 namespace,则拼接在哈希前面(如 litellm.caching.caching:<hash>)。对于内部 HTTP client 缓存,还会在 key 后面附加 event loop ID,防止 “Event loop is closed” 错误。
这意味着:相同的 prompt + 不同的 temperature,会生成不同的 cache key,不会命中缓存。
输入:model + messages + 可选参数(temperature, top_p, tools...)
│
▼
序列化为 JSON → SHA-256 哈希
│
▼
拼接 namespace(如有):litellm.caching.caching:<hash>
四、L1 InMemoryCache
容量:
- 默认上限 200 条(
max_size_in_memory),可配置 - LiteLLM 内部多个组件各自独立实例(LLM 响应缓存、API key 缓存、Router 健康状态缓存等),互不干扰
淘汰机制:
每次
set_cache时触发evict_cache(),两步执行:
Step 1:删除所有已过期的 key(current_time > ttl)
Step 2:若容量仍满,按 TTL 最早到期排序,删除最先过期的直到腾出空间
算法是 Earliest-Expiry-First,不是 LRU,没有访问频率感知。 TTL:
- 通过
default_in_memory_ttl配置(单位秒) - 默认
None,即不主动过期,只靠容量触发淘汰 - 建议:
default_in_memory_ttl ≤ default_in_redis_ttl,避免 L2 过期但 L1 还命中旧数据
五、L2 RedisCache
容量:
- 无硬性限制,由 Redis 实例的
maxmemory+maxmemory-policy决定 - 推荐生产配置
allkeys-lru,让 Redis 自动按访问频率淘汰冷数据 TTL: - 写入时通过
SET key value EX ttl设置,Redis 原生到期后自动删除 - 通过
default_in_redis_ttl或全局ttl配置 高可用模式:
| 模式 | 配置参数 | 适用场景 |
|---|---|---|
| Standalone | host / port / password | 开发/单机 |
| Cluster | redis_startup_nodes | 横向扩展 |
| Sentinel | sentinel_nodes / service_name | 主从高可用 |
初始化逻辑在 litellm/_redis.py,根据配置中是否有 startup_nodes 或 sentinel_nodes 自动选择 client 类型。 |
Circuit Breaker(熔断器) Redis 不可用时自动熔断,三态切换:
CLOSED(正常)
│ 失败次数超阈值
▼
OPEN(熔断,跳过所有 Redis 调用)
│ 等待冷却期
▼
HALF_OPEN(探测一次)
├── 成功 → 回到 CLOSED
└── 失败 → 回到 OPEN
OPEN 状态下直接跳过 Redis,避免超时堆积拖垮 Proxy,但此时 L1 仍然正常工作。
六、语义缓存(Semantic Cache)
普通缓存是精确匹配,语义缓存解决”相似但不完全相同的 prompt”命中问题。
两种实现:
- redis-semantic
- 依赖 Redis 的 RediSearch 模块 + redisvl 库
- 在 Redis 内部做向量检索,存储和检索一体
- qdrant-semantic
- 向量存储在 Qdrant,响应内容仍在 Redis/内存
- 支持 binary / product / scalar 三种量化,向量维度必须与 embedding 模型匹配
语义缓存工作流:
新 Request
│
▼
对 prompt 生成 embedding
│
▼
在向量库中做 ANN 搜索
│
├── 相似度 >= threshold → 返回缓存响应
└── 相似度 < threshold
▼
调用 LLM,将 (prompt_embedding, response) 存入向量库
关键参数:
similarity_threshold: 0.8 # 0=完全不同,1=完全一致
redis_semantic_cache_embedding_model: "text-embedding-ada-002"
七、动态缓存控制
每个请求可通过 cache 字段覆盖全局配置:
| 参数 | 作用 |
|---|---|
no-cache: true | 跳过读缓存,强制调用 LLM,但结果仍会写缓存 |
no-store: true | 跳过写缓存,响应不会被存储 |
ttl: 300 | 覆盖本次请求的 TTL |
s-maxage: 60 | 只接受 60 秒内的缓存响应,更旧的视为 miss |
八、支持的调用类型
Cache 初始化时通过 supported_call_types 参数控制哪些接口类型走缓存,支持 completion、acompletion、embedding、aembedding、atranscription、transcription。
总结
┌──────────────────────────┐
│ LLMCachingHandler │
│ │
│ pre_call: get_cache() → cache hit? 直接返回 │
│ post_call: add_cache() → 写入缓存后端 │
└──────────────────────────┘
│
▼
┌──────────────────────────┐
│ DualCache │
│ L1: InMemory (快) │
│ L2: Redis (共享) │
└──────────────────────────┘
│
配置 redis-semantic 或 qdrant-semantic 时
▼
┌──────────────────────────┐
│ Semantic Cache │
│ embedding → ANN 搜索 │
│ similarity threshold │
└──────────────────────────┘
核心设计思路是:精确匹配用 DualCache 保证速度,语义匹配用向量搜索提高命中率,Circuit Breaker 保证 Redis 故障时 Proxy 继续可用。
MCP 与 A2A 协议支持
一、整体定位
LiteLLM Proxy 同时支持两种 Agent 协议,扮演统一 Gateway 角色:
| 协议 | 设计目标 | LiteLLM 的角色 |
|---|---|---|
| MCP | LLM 调用外部工具 | MCP Gateway:聚合多个 MCP Server,向外暴露统一工具端点 |
| A2A | Agent 调用 Agent | Agent Gateway:代理连接各平台 Agent,统一管理调用和治理 |
外部客户端 (Cursor / Claude Desktop / SDK)
│
▼
┌─────────────────────────────────────────┐
│ LiteLLM Proxy │
│ │
│ /mcp ← MCP Gateway 端点 │
│ /a2a/{name} ← A2A Gateway 端点 │
│ /v1/chat/completions ← 兼容两者 │
│ /v1/agents ← Agent 注册表 │
└─────────────────────────────────────────┘
│ │
▼ ▼
MCP Servers A2A Agents
(工具服务) (LangGraph / Vertex /
Azure / Bedrock / Pydantic AI)
两个协议共用同一套 LiteLLM 治理体系:Virtual Key 鉴权、Team 权限、日志、计费、Guardrail。
二、MCP 协议支持
2.1 引入版本与规范
MCP 从 v1.65.0-stable(2025年3月)正式引入,当前协议版本从 v1.80.18 起升级为 2025-11-25 规范。
2.2 三种传输协议
MCPServerManager 支持 sse、http(Streamable HTTP)、stdio 三种传输方式。
| 传输 | 适用场景 | 特点 |
|---|---|---|
| Streamable HTTP | 远程服务器,生产推荐 | 单端点、无状态、支持水平扩展、OAuth 2.1 |
| SSE | 兼容旧版远程服务器 | 双端点,有状态长连接,逐步被淘汰 |
| stdio | 本地子进程 | LiteLLM 管理进程生命周期,注入环境变量 |
litellm_settings:
mcp_servers:
deepwiki_mcp:
url: "https://mcp.deepwiki.com/mcp" # Streamable HTTP
zapier_mcp:
url: "https://actions.zapier.com/mcp/sse" # SSE
circleci_mcp:
transport: "stdio"
command: "npx"
args: ["-y", "@circleci/mcp-server-circleci"]
env:
CIRCLECI_TOKEN: "your-token"
2.3 工具命名与路由
为防止多 Server 工具名冲突,MCPServerManager 自动将工具名前缀以服务器名称(如 github-create_issue),命名须符合 SEP-986 规范。路由时根据工具名前缀识别目标 Server,再通过对应传输执行调用。
支持配置别名简化引用:
litellm_settings:
mcp_aliases:
"github": "github_mcp_server"
"zapier": "zapier_mcp_server"
2.4 两种使用模式
模式 A:Gateway 模式 外部 MCP 客户端把 LiteLLM Proxy 整体当作一个 MCP Server:
// Cursor 配置
{
"mcpServers": {
"LiteLLM": {
"url": "http://localhost:4000/mcp",
"headers": { "x-litellm-api-key": "Bearer sk-xxx" }
}
}
}
模式 B:Tool Bridge 模式
在 /v1/chat/completions 或 /v1/responses 中声明 MCP 工具,LiteLLM 作为 MCP Client 自动完成工具发现 → 调用 → 结果回填的完整循环:
Tool Discovery → LiteLLM 拉取 MCP 工具定义并转换为 OpenAI-compatible schema;LLM Call → 工具定义随 input 发给 LLM,LLM 决定调用哪个工具;Tool Execution → LiteLLM 解析参数、路由到对应 MCP Server 执行;Response Integration → 结果追加到对话,再次调用 LLM 生成最终答案。
response = client.responses.create(
model="gpt-4o",
input=[{"role": "user", "content": "..."}],
tools=[{
"type": "mcp",
"server_label": "litellm",
"server_url": "litellm_proxy/mcp",
"require_approval": "never",
"allowed_tools": ["github-create_issue"] # 可限制可用工具
}]
)
2.5 认证体系
入方向(客户端 → LiteLLM) 使用 LiteLLM Virtual Key,支持 Key 级别和 Team 级别权限控制,内置短期内存缓存减少数据库查询。
出方向(LiteLLM → MCP Server)
支持 OAuth 2.0(authorization_code 和 client_credentials 两种 flow);AWS SigV4(专用于 Bedrock AgentCore);静态/转发 Header。
OAuth 支持自动发现:设置认证类型为 OAuth 后,LiteLLM 自动定位 Provider metadata、动态注册 client、执行 PKCE 授权,无需手动配置。
2.6 公网访问控制
基于调用者 IP 区分内网/公网(默认以 RFC 1918 私有地址段为内网)。内网调用者可见全部 MCP Server,外网调用者只能访问标记了 available_on_public_internet: true 的 Server。过滤应用于所有访问点:注册表、工具列表、工具调用、动态路由和 OAuth 发现端点。
2.7 存储与持久化
MCP Server 配置支持两种方式:
- config.yaml:静态声明,重启生效
- 数据库:
store_model_in_db: true启用,支持运行时动态增删,与 model、guardrail 共用同一持久化机制
2.8 核心模块位置
litellm/proxy/_experimental/mcp_server/
├── mcp_server_manager.py # Server 注册表、工具前缀、路由分发
├── server.py # 请求处理、日志采集入口
├── auth/
│ └── user_api_key_auth_mcp.py # 客户端 Virtual Key 验证
└── ...
litellm/types/mcp_server/
└── mcp_server_manager.py # MCPServer Pydantic 模型定义
三、A2A 协议支持
3.1 引入版本
A2A Agent Gateway 从 v1.80.8-stable 引入,每次 Agent 调用记录到 LiteLLM Logs,复用与 LLM API 相同的访问控制和计费体系。
3.2 A2A 协议基础
A2A 基于 JSON-RPC 2.0 over HTTP(S),三个核心概念:Agent Card(能力描述与发现)、Task(任务生命周期)、Artifact(任务输出物)。
消息结构
// 请求
{
"jsonrpc": "2.0",
"id": "request-id",
"method": "message/send",
"params": {
"message": {
"role": "user",
"parts": [{"kind": "text", "text": "Your message"}],
"messageId": "msg-id",
"contextId": "ctx-id" // 可选,跨 Task 的上下文复用
}
}
}
// 响应
{
"jsonrpc": "2.0",
"id": "request-id",
"result": {
"kind": "task",
"id": "task-id",
"contextId": "ctx-id",
"status": {"state": "completed", "timestamp": "..."},
"artifacts": [{
"artifactId": "artifact-id",
"parts": [{"kind": "text", "text": "Agent response"}]
}]
}
}
contextId 可跨越单个 Task 生命周期,支持多轮对话上下文持久化。
3.3 支持的 Agent 平台
支持 LangGraph、Vertex AI Agent Engine、Azure AI Foundry、Bedrock AgentCore、Pydantic AI,各平台通过 Admin UI 填写调用 URL 完成统一注册。
3.4 两种调用接口
接口一:原生 A2A SDK
将 A2AClient 的 base_url 指向 /a2a/{agent_name},使用 LiteLLM Virtual Key 鉴权,完整支持 A2A 协议的 tasks、artifacts、streaming。
base_url = "http://localhost:4000/a2a/my-agent"
headers = {"Authorization": "Bearer sk-1234"}
async with httpx.AsyncClient(headers=headers) as httpx_client:
resolver = A2ACardResolver(httpx_client=httpx_client, base_url=base_url)
agent_card = await resolver.get_agent_card()
client = A2AClient(httpx_client=httpx_client, agent_card=agent_card)
response = await client.send_message(request)
接口二:OpenAI SDK 兼容
将 model 字段设为 a2a/{agent_name},LiteLLM 自动将请求转换为 A2A 协议并路由,结果转换回 OpenAI choices 格式,支持流式。
# 同步
response = client.chat.completions.create(
model="a2a/my-agent",
messages=[{"role": "user", "content": "Hello"}]
)
# 流式
stream = client.chat.completions.create(
model="a2a/my-agent",
messages=[{"role": "user", "content": "..."}],
stream=True
)
3.5 Agent 注册表端点
GET /v1/agents → 列出当前 Key 有权访问的所有 Agent
POST /v1/agents → 注册新 Agent
GET /a2a/{agent_name} → 获取 Agent Card
POST /a2a/{agent_name} → 向指定 Agent 发 A2A 消息
AI Hub 作为组织内部的 Agent 发现中心,开发者可浏览所有公开注册的 Agent,无需自己重新构建。
3.6 认证体系(双向)
入方向: 与 LLM 调用一致,使用 LiteLLM Virtual Key,支持 Key 和 Team 粒度的 Agent 访问权限。
**出方向:**三种方式可组合:Static Headers(Admin 配置,客户端不可见);Forward Client Headers(Admin 预配置允许名单,Client 提供值);Convention-based Headers(客户端用 x-a2a-{agent_name}-{header} 命名规范,自动路由到对应 Agent,无需 Admin 预配置)。
# 最终发往后端 Agent 的 Headers
X-Internal-Token: secret123 ← static(Admin 配置)
x-user-id: user-42 ← forwarded(Admin 允许,Client 提供值)
x-request-id: req-abc ← convention-based(x-a2a-my-agent-* 前缀)
X-LiteLLM-Trace-Id: <uuid> ← LiteLLM 自动注入
X-LiteLLM-Agent-Id: <agent-id> ← LiteLLM 自动注入
3.7 可观测性
Token 用量和费用从 request/response 自动计算,写入 _hidden_params["usage"],与 LLM 调用共用计费和花费追踪体系。通过 X-LiteLLM-Trace-Id 可将 A2A 调用与上游 LLM 调用关联,实现端到端链路追踪。
四、MCP vs A2A 对比
| 维度 | MCP | A2A |
|---|---|---|
| 设计目标 | LLM 调用工具 | Agent 调用 Agent |
| 通信主体 | LLM ↔ Tool Server | Agent ↔ Agent |
| 传输协议 | Streamable HTTP / SSE / stdio | JSON-RPC 2.0 over HTTP |
| 响应格式 | Tool result(结构化) | Task + Artifact |
| 状态管理 | 无状态 | 有状态(contextId 跨任务) |
| 发现机制 | Tool listing | Agent Card(/.well-known/agent.json) |
| LiteLLM 入口 | /mcp | /a2a/{agent_name} |
| OpenAI 兼容调用 | tools[].type = "mcp" | model = "a2a/{name}" |
| 引入版本 | v1.65.0 | v1.80.8 |
| 规范版本 | MCP 2025-11-25 | A2A JSON-RPC 2.0 |