AGI(Artificial General Intelligence)
通用人工智能,是具备与人类同等智能、或超越人类的人工智能,能表现正常人类所具有的所有智能行为。又名强人工智能
AI(Artificial Intelligence)
人工智能,1956 年于 Dartmouth 学会上提出,一种旨在以类似人类反应的方式对刺激做出反应并从中学习的技术,其理解和判断水平通常只能在人类的专业技能中找到。AI 因具备自主学习和认知能力,可进行自我调整和改进,从而应对更加复杂的任务
AIGC(AI generated content)
人工智能生成内容,是一种内容生产形式。例如 AI 文字续写,文字转像的 AI 图、AI 主持人等,都属于 AIGC 的应用
Agents
Agent(智能体) = 一个设置了一些目标或任务,可以迭代运行的大型语言模型。这与大型语言模型(LLM)在像 ChatGPT 这样的工具中“通常”的使用方式不同。在 ChatGPT 中,你提出一个问题并获得一个答案作为回应。而 Agent 拥有复杂的工作流程,模型本质上可以自我对话,而无需人类驱动每一部分的交互
Transformer
Transformer 模型(直译为“变换器”)是一种采用自注意力机制的深度学习模型,这一机制可以按输入数据各部分重要性的不同而分配不同的权重。该模型主要用于自然语言处理(NLP)与计算机视觉(CV)领域
Prompt Engineering
它是人工智能中的一个概念,特别是自然语言处理(NLP)。 在提示工程中,任务的描述会被嵌入到输入中。提示工程的典型工作方式是将一个或多个任务转换为基于提示的数据集,并通过所谓的“基于提示的学习(prompt-based learning)”来训练语言模型
Pre-training
训练机器学习模型的初始阶段,其中模型从数据中学习一般特征、模式和表示,而无需具体了解稍后将应用于的任务。这种无监督或半监督学习过程使模型能够对底层数据分布有基本的了解,并提取有意义的特征,这些特征可用于随后对特定任务进行微调
RAG(Retrieval-augmented generation)
检索增强生成
Encoder(编码器)
作用:把一段文本 → 压缩成一个语义向量 / 特征表示
- 只 “看懂”,不 “生成”
- 输入:句子
- 输出:语义向量、特征、上下文表示
典型模型
- BERT
- RoBERTa
- Bi-Encoder(向量检索用)
- Cross-Encoder(精排用)
场景
- 把 query 转成向量
- 把文档转成向量
- 计算 query 和文档的相关性
- 做特征提取,给 LTR 用(Cross-Encoder)
Decoder(解码器)
作用:根据前面的内容 → 逐词生成下一个词
- 只 “生成”,不 “压缩”
- 输入:前缀文本 / 提示
- 输出:一句话、一段话

模型
- GPT
- PaLM
- LLaMA
- T5 Decoder 部分
场景
- RAG 最后生成回答
- 写摘要、写标题
- 做 query 改写、扩展
Encoder-Decoder
完整 Transformer
Encoder 理解输入 → Decoder 生成输出
- 机器翻译
- 文本摘要
- T5、BART、Seq2Seq 模型
Pooling
通过某种方法(如取 [CLS] 位的向量、对所有 token 向量求平均 mean pooling 等),将所有 token 的向量压缩成一个单一的向量,这个向量代表了整个文本块的语义。
[CLS] 是 BERT 等 Transformer 模型在输入文本开头添加的特殊标记,它通过自注意力机制动态聚合整个序列的上下文信息,其最终向量被训练用作代表全局语义的嵌入。
KNN
k-Nearest Neighbor,精确最近邻
核心:暴力遍历全量数据,计算查询与所有样本的精确距离,返回最近的 k 个样本。
- 原理
- 计算查询向量与数据集中所有向量的距离(欧氏、余弦、曼哈顿等)。
- 按距离排序,取前 k 个最近邻。
- 分类:多数投票;回归:取均值。
- 复杂度:时间 O(n)(n 为数据量),空间 O(n)。
- 特点:100% 精确、实现简单、无训练阶段(惰性学习)。
- 适用:小数据集、精度要求极高的场景(如医学检索、小规模知识库)。
ANN
Approximate Nearest Neighbor,近似最近邻
核心:牺牲少量精度换取百倍级速度提升,通过索引结构大幅缩小搜索空间。
- 原理
- 离线建索引:用 KD 树、LSH、HNSW、IVF 等结构,把相似向量聚类 / 分组。
- 在线检索:只在候选区域计算距离,不遍历全量数据。
- 结果是近似最近邻,召回率通常 90%–99%。
- 复杂度:时间接近 O(log n),空间较高(需存索引)。
- 特点:速度极快、可扩展到百万 / 亿级向量、需调参平衡精度与速度。
- 适用:大规模向量检索、实时场景(推荐、搜图、RAG、大模型知识库)。
KV Cache
🏷 标签: #LLM/KV-Cache 📒 笔记: [[第二部分:LLM 核心原理#第5章:LLM 的推理原理]]
KV Cache(Key-Value Cache,键值缓存) 是大型语言模型(LLM)在推理(Inference)阶段的一项核心加速技术,尤其在 Transformer 架构的 Decoder-only 模型(如 GPT、Llama、Qwen 等)中广泛使用。
它的本质是:用空间换时间,缓存自注意力(Self-Attention)机制中已经计算过的 Key(K) 和 Value(V) 张量,避免在生成每个新 token 时重复计算历史上下文,从而将计算复杂度从 O(n²) 降低到 O(n),推理速度可提升 4~10 倍 甚至更多(具体取决于上下文长度)。
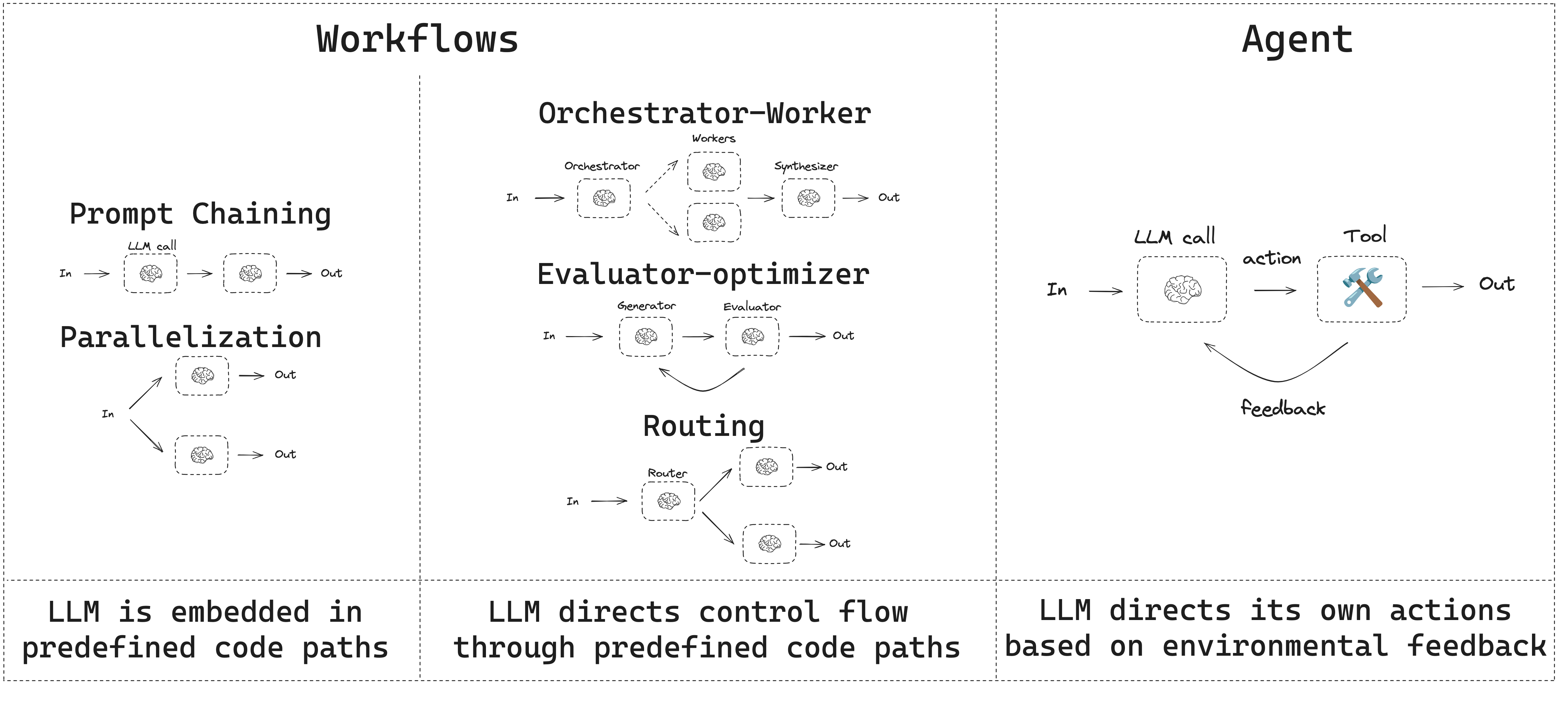
WorkFlow vs Agent
- 工作流 workflow 是通过预定义代码路径编排 LLM 和工具的系统。
- 智能体 agent 则是 LLM 动态指导其自身流程和工具使用的系统,它们能自主控制如何完成任务。
Skills
将 Agent Skills 想象成 AI 助理的「使用指南」。AI 不需要预先知道所有事情,技能让它可以随时学习新能力,就像给人一张食谱卡,而不是让他们背诵整本食谱书。
技能是简单的文本文件(称为 SKILL.md),教导 AI 如何执行特定任务。当你请求 AI 做某件事时,它会找到正确的技能,阅读指令,然后开始工作。
技能分三个阶段加载:
- 浏览 - AI 看到可用技能列表(只有名称和简短描述)
- 加载 - 当需要技能时,AI 会阅读完整指令
- 使用 - AI 遵循指令并访问任何辅助文件
优点:
- 更快更轻量 - AI 只在需要时加载所需内容
- 跨平台使用 - 创建一次技能,在任何兼容的 AI 工具中使用
- 易于分享 - 技能只是可以复制、下载或在 GitHub 分享的文件
技能是指令,不是代码。AI 像人阅读指南一样阅读它们,然后遵循步骤。
示例:
---
name: github-actions-failure-debugging
description: 调试失败的 GitHub Actions 工作流程的指南。
---
调试失败的 GitHub Actions 工作流程:
1. 使用 `list_workflow_runs` 查找最近的工作流程运行
2. 使用 `summarize_job_log_failures` 获取失败作业的 AI 摘要
3. 如需详细失败日志,使用 `get_job_logs`
4. 尝试在你的环境中重现故障
5. 修复失败的构建
- SKILL.md 的作用是给 Agent 提供一个高层次的工作流程指南(就像一份“使用手册”)。
- 反引号
list_workflow_runs标记的就是 Agent 实际能调用的 Tool Name。 - 这些 Tool 背后可能是:
- 封装好的 Python 函数
- API 调用
- 内部服务
- 甚至是另一个子 Agent
- 但在 SKILL.md 里,你不需要写具体的实现代码,只需要写出工具的名字和使用步骤。
skill 实现:skill.md + tool call
UV
UV(Ultrafast Virtualenv)是一个由 Astral 团队开发的新一代 Python 包管理工具,于 2023 年推出。它的设计目标是解决 Python 包管理中的速度和依赖解析问题,使 Python 开发更加流畅高效。UV 由 Rust 语言编写,这使它在性能上有显著优势。
| 工具 | 设计哲学 | 最适用场景 |
|---|---|---|
| UV | 极速、安全的Python包管理 | Python Web开发、一般Python项目 |
| conda | 全语言包管理系统 | 数据科学、跨语言项目、需要系统级依赖的项目 |
| pip | Python官方包安装工具 | 简单Python项目、作为其他工具的后端 |