Algorithm
查找算法
二分查找
- 数组必须是有序的
- mid = left + (right - left) / 2
- 如果定义的区间是
[left, right](左闭右闭),那么当left == right时,区间内还有一个元素,所以循环条件必须是<=。同时,既然mid已经检查过了且不是目标,新区间就要跳过mid。 - 如果
right更新逻辑是right = mid而不是mid - 1,且循环条件是left < right,在某些情况下(如只有两个元素时)可能会陷入死循环。务必保持逻辑自洽。
class Solution {
public int search(int[] nums, int target) {
// 1. 初始化左右指针
int left = 0;
int right = nums.length - 1;
// 2. 采用左闭右闭区间 [left, right]
while (left <= right) {
// 3. 防溢出的中点计算
int mid = left + (right - left) / 2;
if (nums[mid] == target) {
return mid; // 找到了
} else if (nums[mid] < target) {
// target 在右区间,所以调整左边界
left = mid + 1;
} else {
// target 在左区间,所以调整右边界
right = mid - 1;
}
}
// 4. 没找到,返回 -1
return -1;
}
}
深度优先搜索(回溯)
分类判断分支逻辑,重复调用自身方法,相当于从根节点搜索到叶子节点然后返回
树的深度:

实现方式:
- 递归实现(最常用,贴合 “回溯” 逻辑) 递归的本质是利用系统栈保存 “当前路径状态”,递归调用对应 “深入”,递归返回对应 “回溯”。通用模板(以树的遍历为例):
def dfs(node):
# 1. 终止条件(递归出口:走到“死胡同”)
if node is None:
return
# 2. 处理当前节点(比如记录值、判断条件)
process(node)
# 3. 递归遍历子节点(深入下一层)
dfs(node.left) # 先探左子树到底
dfs(node.right) # 左子树探完,再探右子树
- 栈实现(手动模拟递归,避免递归栈溢出) 用栈手动保存待遍历的节点,每次弹出栈顶节点处理,再将子节点(反向入栈,保证遍历顺序)压入栈,核心是 “后进先出”。通用模板(以树的遍历为例):
def dfs(root):
if root is None:
return
stack = [root] # 初始化栈,压入起始节点
while stack:
node = stack.pop() # 弹出栈顶(当前节点)
process(node) # 处理当前节点
# 注意:栈是后进先出,想先遍历左子树则先压右子树
if node.right:
stack.append(node.right)
if node.left:
stack.append(node.left)
例题:图的 DFS
Given an `m x n` grid of characters `board` and a string `word`, return `true` _if_ `word` _exists in the grid_.
The word can be constructed from letters of sequentially adjacent cells, where adjacent cells are horizontally or vertically neighboring. The same letter cell may not be used more than once.
Input: board = [["A","B","C","E"],["S","F","C","S"],["A","D","E","E"]], word = "ABCCED"
Output: true

class Solution {
private boolean isFound;
public boolean exist(char[][] board, String word) {
isFound = false;
int m = board.length;
int n = board[0].length;
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
dfs(board, word, i, j, 0);
if (isFound)
return true;
}
}
return false;
}
private void dfs(char[][] board, String word, int i, int j, int p) {
// 找到单词
if (p == word.length()) {
isFound = true;
return;
}
if (isFound) {
return;
}
// 越界
if (i < 0 || i >= board.length || j < 0 || j >= board[0].length) {
return;
}
// 单词不相同,查找失败
if (board[i][j] != word.charAt(p)) {
return;
}
// p 位单词相同,标记已查找(用负号表示),继续查找
board[i][j] = (char) (-board[i][j]);
dfs(board, word, i + 1, j, p + 1);
dfs(board, word, i - 1, j, p + 1);
dfs(board, word, i, j + 1, p + 1);
dfs(board, word, i, j - 1, p + 1);
board[i][j] = (char) (-board[i][j]);
}
}
DP 动态规划
解决有重叠子问题和最优子结构问题的高效算法思想,核心是「用已解决的子问题答案推导当前问题答案」,通过记录子问题的解(状态)避免重复计算,以空间换时间。因为需要用一个数组存储计算结果,也称为:记忆化搜索/带备忘录的递归/递归树的剪枝。
注意:如果是解决 m*n 数组路径问题,只要 m 或者 n 超过 50,就不能用递归,否则会超时甚至栈溢出。
实现方式:
- 递归 重复调用函数,对函数调用栈不友好
- 迭代 两个 for 循环 解法: 思考:怎么把文字拆成子问题,确定能不能用动态规划。
- 定义状态:思考 DP 存什么,即 dp[i] 或 dp[i][j] 中 i 或 j 要代表什么
- base case:存入基本状态
- 状态转移方程:状态更新公式逻辑
- return 值:怎么根据状态方程寻找 return 值
例题
例题:最大子数组合
Given an integer array `nums`, find the subarray with the largest sum, and return its sum.
Input: nums = [-2,1,-3,4,-1,2,1,-5,4]
Output: 6
Explanation: The subarray [4,-1,2,1] has the largest sum 6.
class Solution {
public int maxSubArray(int[] nums) {
// 1.定义状态:dp[i] 表示 以第 i 个元素结尾的最大子数组和
int[] dp = new int[nums.length];
// 2.Base Case(初始状态)
dp[0] = nums[0];
// 3.状态转移方程(状态更新公式):dp[i] = Max(dp[i-1] + nums[i], nums[i]),注意是以 i 结尾
for (int i = 1; i < nums.length; i++) {
dp[i] = Math.max(dp[i - 1] + nums[i], nums[i]);
}
// 4.return 值:结果就是 dp 方程最大值
int res = Integer.MIN_VALUE;
for (int i = 0; i < dp.length; i++) {
if (res < dp[i])
res = dp[i];
}
return res;
}
}
例题:动态规划
更抽象的题目:动态规划就是抽象,把题目抽象化,不要纠结题目的实现细节,抓住 dp 公式的思想!
Given two strings `word1` and `word2`, return _the minimum number of operations required to convert `word1` to `word2`_.
You have the following three operations permitted on a word:
- Insert a character
- Delete a character
- Replace a character
Input: word1 = "horse", word2 = "ros"
Output: 3
Explanation:
horse -> rorse (replace 'h' with 'r')
rorse -> rose (remove 'r')
rose -> ros (remove 'e')
class Solution {
public int minDistance(String word1, String word2) {
// dp 思路:dp[i]:i 表示 word1 前 i 个字符转换成 word2 最小转换次数
// dp[i]:需要判断 word1[i] 和 word2 所有字符相等情况 —》dp[i][j]
// dp[i][j]:只需要判断 word[i] 和 word[j] 相等情况,然后判断删除/新增/替换操作
// 需要考虑word1和word2空字符情况,即 i/j = 0
int m = word1.length() + 1, n = word2.length() + 1;
int[][] dp = new int[m][n];
// base case
dp[0][0] = 0;
for (int i = 1; i < m; i++) {
// word1不为空(长度为i),word2为空, word1->word2 删除操作:i 次
dp[i][0] = i;
}
for (int j = 1; j < n; j++) {
// word1为空,word2不为空(长度为j), word1->word2 新增操作:j 次
dp[0][j] = j;
}
// 不要纠结匹配细节,dp[i][j] 是已经确定 word1[0~i] 和 word2[0~j] 相等要操作 word1 的最小次数
for (int i = 1; i < m; i++) {
for (int j = 1; j < n; j++) {
if (word1.charAt(i - 1) == word2.charAt(j - 1)) {
// 字符相等,操作数为 0;等于把 word1[i] 和 word2[j] 字符删除后的 dp[i-1][j-1]
dp[i][j] = dp[i - 1][j - 1];
} else {
dp[i][j] = min(
// 已经确定word1(0~i)->word2(0~j-1)的最小操作数是dp[i][j-1]
// 现在word2多了1位,word1跟着新增一位,就可以使得word1(0~i)->word2(0~j)
dp[i][j - 1] + 1,
// 已经确定word1(0~i-1)->word2(0~j)的最小操作数是dp[i-1][j]
// 现在word1多了1位,只要把这一位删掉,就可以使得word1(0~i)->word2(0~j)
dp[i - 1][j] + 1,
// 已经确定word1(0~i-1)->word2(0~j-1)的最小操作数是dp[i-1][j-1]
// 现在word1和word2都多了1位,只需要把这一位替换,就可以使得word1(0~i)->word2(0~j)
dp[i - 1][j - 1] + 1);
}
}
}
return dp[m - 1][n - 1];
}
private int min(int a, int b, int c) {
return Math.min(a, Math.min(b, c));
}
}
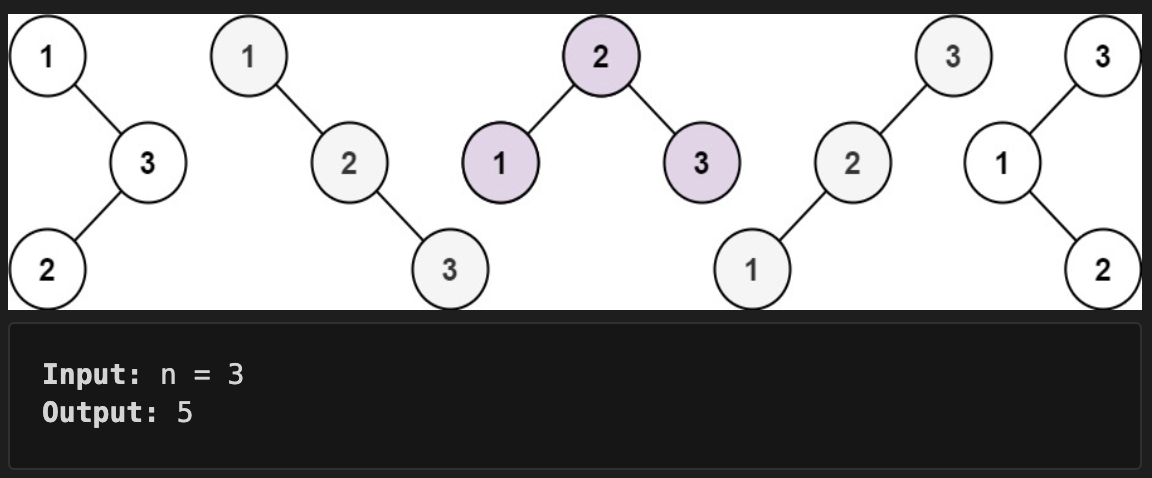
例题:二叉搜索数
BST(binary search tree):二叉搜索树:左子树小于根节点,右子树大于根节点
Given an integer n, return the number of structurally unique BST's (binary search trees) which has exactly n nodes of unique values from 1 to n.
class Solution {
public int numTrees(int n) {
// BST:二叉搜索树:左子树小于根节点,右子树大于根节点
// 动态规划解法:给你 n 个节点,当以 i 为根节点时
// 1.[1, i-1] 个数归到左子树,假设解法为 f(i-1)
// 2.[i+1, n] 个数归到右节点,这里子树构建方式的数量和值无关,只和
// 节点数量有关,所以会有一个重复计算的过程,当左子树数量为 i - 1
// 时,右子树数量为 n - (i - 1) - 1 = n - i, 假设解法为f(n-i)
// 3. 以 i 为子节点时,解法为 f(i-1)*f(n-i)
// 4. f(k) 代表 k 个节点的解法,f(k) = sum{f(i-1)*f(k-i)},[i=1~k];
// base case
int[] dp = new int[n + 1];
dp[0] = 1; // 特殊值,不然怎么乘都等于 0,解法不会为 0 种
dp[1] = 1;
for (int k = 2; k <= n; k++) {
for (int i = 1; i <= k; i++) {
dp[k] += dp[i - 1] * dp[k - i];
}
}
return dp[n];
}
}
贪心算法
动态规划或者递归回溯都可以考虑能否用贪心算法。问题必须具有 贪心选择性质 和 最优子结构性质。
核心思想:
- 局部最优 每一步都做出当前看起来最好的选择,不考虑整体的长远影响。
- 无后效性 一旦做出选择,就不会再回溯修改之前的决策。
例题:跳跃数组
You are given an integer array `nums`. You are initially positioned at the array's first index, and each element in the array represents your maximum jump length at that position.
Return `true` _if you can reach the last index, or_ `false` _otherwise_.
Input: nums = [2,3,1,1,4]
Output: true
Explanation: Jump 1 step from index 0 to 1, then 3 steps to the last index.
// 维护当前能到达的最远位置,遍历数组时不断更新这个最远位置,若最远位置能覆盖最后一个索引,则返回 `true`
class Solution {
public boolean canJump(int[] nums) {
int maxReachIndice = 0;
for (int i = 0; i < nums.length; i++) {
// 判断能否到达当前位置
if (i > maxReachIndice)
return false;
// 可以到达当前位置,更新最大到达位置,判断是否可以到达终点
maxReachIndice = Math.max(maxReachIndice, i + nums[i]);
if (maxReachIndice >= nums.length - 1)
return true;
}
return false;
}
}
位运算
例题:Hamming Distance
The **Hamming distance** between two integers is the number of positions at which the corresponding bits are different.
Given two integers `x` and `y`, return the **Hamming distance** between them.
Input: x = 1, y = 4
Output: 2
Explanation:
1 (0 0 0 1)
4 (0 1 0 0)
↑ ↑
class Solution {
public int hammingDistance(int x, int y) {
// 1. 异或运算:对 `x` 和 `y` 执行异或操作(`x ^ y`),异或的特性是**对应位相同则为 0,不同则为 1
// 统计 1 的数量:统计异或结果中 1 的个数,即为汉明距离。
int xor = x ^ y;
int count = 0;
// 2. n & (n - 1) :每次执行都会把 n 二进制中「最后一个 1」变成 0
// 循环处理直至 xor 结果为 0
while (xor != 0) {
xor &= xor - 1;
count++;
}
return count;
}
}
Data Structure
优先队列/最小堆
PriorityQueue 默认是小顶堆,顶部/头部元素最小,插入是在尾部插入,插入元素通过 siftUp 调整位置
// 默认升序
PriorityQueue<Integer> pq = new PriorityQueue<>();
// 降序
PriorityQueue<Integer> maxHeap = new PriorityQueue<>((a, b) -> b - a);
// Comparator 实现自定义排序
PriorityQueue<String> strPQ = new PriorityQueue<>((s1, s2) -> {
// 按字符串长度升序,长度相同按字典序
if (s1.length() != s2.length()) {
return s1.length() - s2.length(); // 长度升序
}
return s1.compareTo(s2); // 长度相同,字典序升序
});
// Comparetor 比较器:
PriorityQueue<Map.Entry<Integer, Integer>> minHeap = new PriorityQueue<>(Comparator.comparingInt(Map.Entry::getValue));
// 注意:加入其他类时,如果类没有实现 Comparable 接口,则要实现接口或者创建队列时传入自定义 Comparator:
PriorityQueue<ListNode> pq = new PriorityQueue<>(new Comparator<ListNode>() {
@Override
public int compare(ListNode o1, ListNode o2) {
// 升序:o1.val - o2.val;降序:o2.val - o1.val
return o1.val - o2.val;
}
});
// Lambda 简化写法
PriorityQueue<ListNode> pq = new PriorityQueue<>((o1, o2) -> o1.val - o2.val);
| 方法 | 作用 | 异常 / 返回值 |
|---|---|---|
offer(E e) | 入队 | 成功返回 true,失败返回 false |
add(E e) | 入队(继承自 Collection) | 成功返回 true,失败抛 IllegalStateException |
peek() | 查看队首(优先级最高) | 队空返回 null |
poll() | 出队(弹出队首) | 队空返回 null |
remove() | 出队(弹出队首,继承自 Queue) | 队空抛 NoSuchElementException |
isEmpty() | 判断队列是否为空 | 空返回 true,否则 false |
size() | 获取队列元素个数 | 返回 int 类型长度 |
LinkedList
在 Java 中,LinkedList 同时实现了 List、Queue 和 Deque 接口(Deque 继承自 Queue)
| 接口 | 核心特性 | 核心用法 |
|---|---|---|
| Queue | 单端 FIFO,仅队尾入、队首出 | 普通队列(任务排队),offer/poll/peek |
| Deque | 双端操作,继承 Queue | 双端队列 / 栈 / 滑动窗口,addFirst/removeLast/push/pop |
| List | 有序可索引,增删改查 | 动态列表存储,get/set/add (index,e)/remove (index) |
- 仅 FIFO 队列:Queue + offer/poll/peek
- 双端 / 栈操作:Deque + addFirst/removeLast/push/pop(add 也可以替换成 offer)
- 索引化有序存储:List + get/set/add (index,e)
Deque(双端队列)和 Stack(栈)都能实现「后进先出(LIFO)」的栈操作,但 Stack 是遗留类,Deque 是现代标准实现。方法:push/peek/pop
算法题中,栈多用 Deque:
Deque<Integer> stack = new ArrayDeque<>();
问题分类
背包问题
基础类型
- 0-1 背包问题:每个物品最多选 1 次(不可重复选择)
- 完全背包问题:每个物品可无限次选择(可重复选择)
- (拓展)多重背包:每个物品有固定数量上限
- (拓展)混合背包:同时存在 0-1、完全、多重等多种物品类型
| 类型 | 物品选择限制 | 遍历顺序(一维 DP) |
|---|---|---|
| 0-1 背包 | 不可重复选 | 容量从大到小倒序遍历 |
| 完全背包 | 可重复选 | 容量从小到大正序遍历 |
常用解法:动态规划
-
问题转化
- 背包问题本质是:在有限约束下,求最优组合
- 约束:背包容量 / 目标和 / 最大重量等
- 目标:最大价值 / 最小硬币数 / 是否可达等
-
状态定义 一维 DP(空间优化版):
dp[j]:在容量为j时,能达到的最优状态(最大价值 / 是否可达 / 最少硬币数等) -
状态转移
- 0-1 背包:
for (int i = 0; i < n; i++) { // 遍历物品 for (int j = target; j >= w[i]; j--) { // 倒序遍历容量 dp[j] = max(dp[j], dp[j - w[i]] + v[i]); } }- 完全背包:
for (int i = 0; i < n; i++) { // 遍历物品 for (int j = w[i]; j <= target; j++) { // 正序遍历容量 dp[j] = max(dp[j], dp[j - w[i]] + v[i]); } } -
初始化
- 目标为最大价值:
dp[0] = 0,其余初始化为-∞(表示不可达) - 目标为是否可达:
dp[0] = true,其余初始化为false - 目标为最少硬币数:
dp[0] = 0,其余初始化为大数(如amount + 1)
- 目标为最大价值:
常用技巧
- 先判断总和奇偶:若目标和为奇数,直接返回不可达(如 LeetCode 416)
- 提前剪枝:若单个物品重量 > 目标容量,直接跳过该物品
- 提前终止:若
dp[target]已达到最优,可提前结束循环 - 一维 DP 优化:将二维状态
dp[i][j]压缩为一维dp[j],空间复杂度从 O (n・target) 降至 O (target)